RAGFlow
此應用程式以 RAGFLow 為基礎進行修改。GenAI Studio 對 RAGFlow 的核心進行了封裝,並提供完整的操作介面,幫助企業團隊無需寫任何程式即可建立企業級智能知識庫與問答系統。
RAGFlow 的核心優勢在於其精細的文件解析能力,針對排版或內容較為複雜的 PDF、掃描檔、或表格等, 除了能辨識文件結構、保留語意完整性,更顯著的提升了檢索與問答的準確率,避免傳統 RAG 因文字切片粗糙而導致的答案缺失問題。
安裝應用程式
和其它應用程式一樣,要安裝 RAGFlow 也必須取得安裝檔 (檔名為 ragflow-App_v1.0.0_setup.run,約 5GB),
取得安裝檔後,執行命令
chmod +x ragflow-App_v1.0.0_setup.run && ./ragflow-App_v1.0.0_setup.run
然後只要依照安裝向導進行安裝即可完成部暑。
安裝檔的檔名自帶了版本號,有可能和上述說明中的檔名不同,如 ragflow-App_v1.1.0_setup.run。
開始使用
取得 GenAI Studio 的金鑰
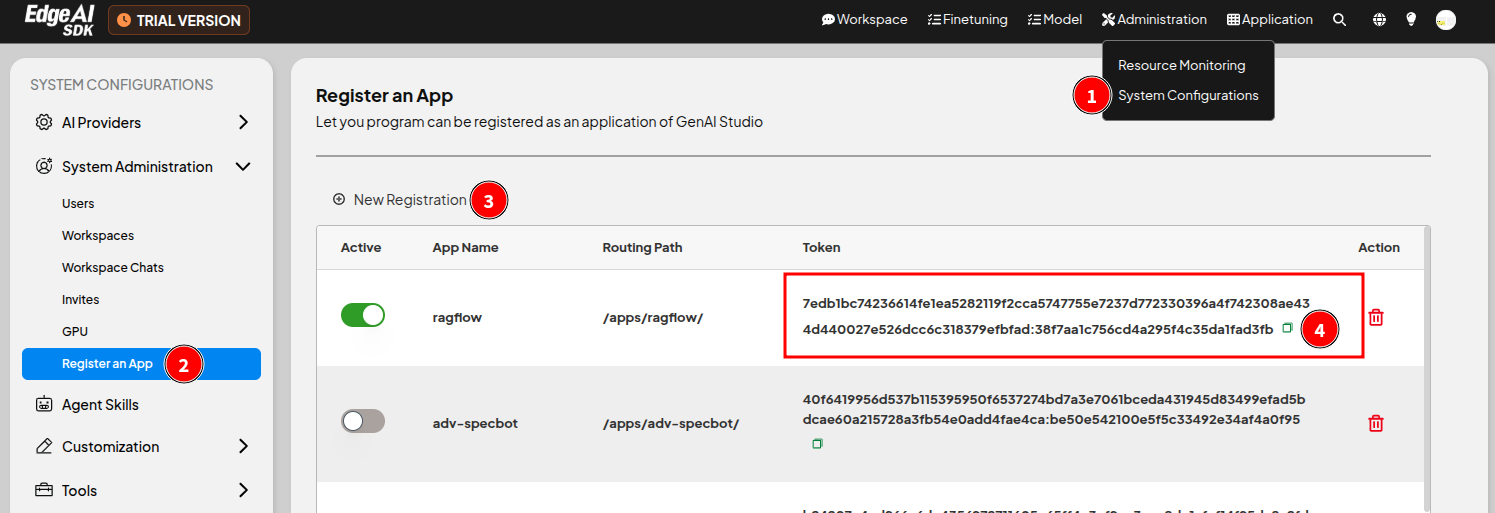
首先,請先在 GenAI Studio 中為本應用程式進行註冊,並取得專屬的金鑰:
- 登入 GenAI Studio。
- 點擊頁面右上角選單 系統管理 > 系統設定 來開啟 系統配置 頁面。
- 在側邊欄中點擊 系統管理 > App 註冊 進入 App 註冊 頁面。
- 點擊 ㊉ 註冊新的App,在開啟的視窗中填入 ragflow 並按下 確認。
- 將專屬於本應用程式的金鑰記錄下來以備後續使用。
修改設定檔
本應用程式的設定檔位於 $HOME/Advantech/GenAI-Studio-Apps/ragflow-App/etc/config.ini,
請使用您偏好的文字編輯器開啟該檔案,修改 [gais] 段落,將上個步驟取得的金鑰填入 token 設定,
如下:
[gais]
host = server
port = 3001
protocol = 1.0
token = <註冊時拿到的專屬金鑰>
啟動應用程式
設定檔修改完成後,執行以下命令將應用程式啟動
cd ~/Advantech/GenAI-Studio-Apps/ragflow-App/bin
./app-up
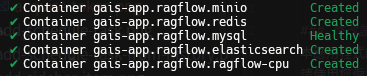
隨後,在終端機畫面上會顯示應用程式內各容器的狀態,若其狀態為 Started 或 Healthy
即代表一切正常。
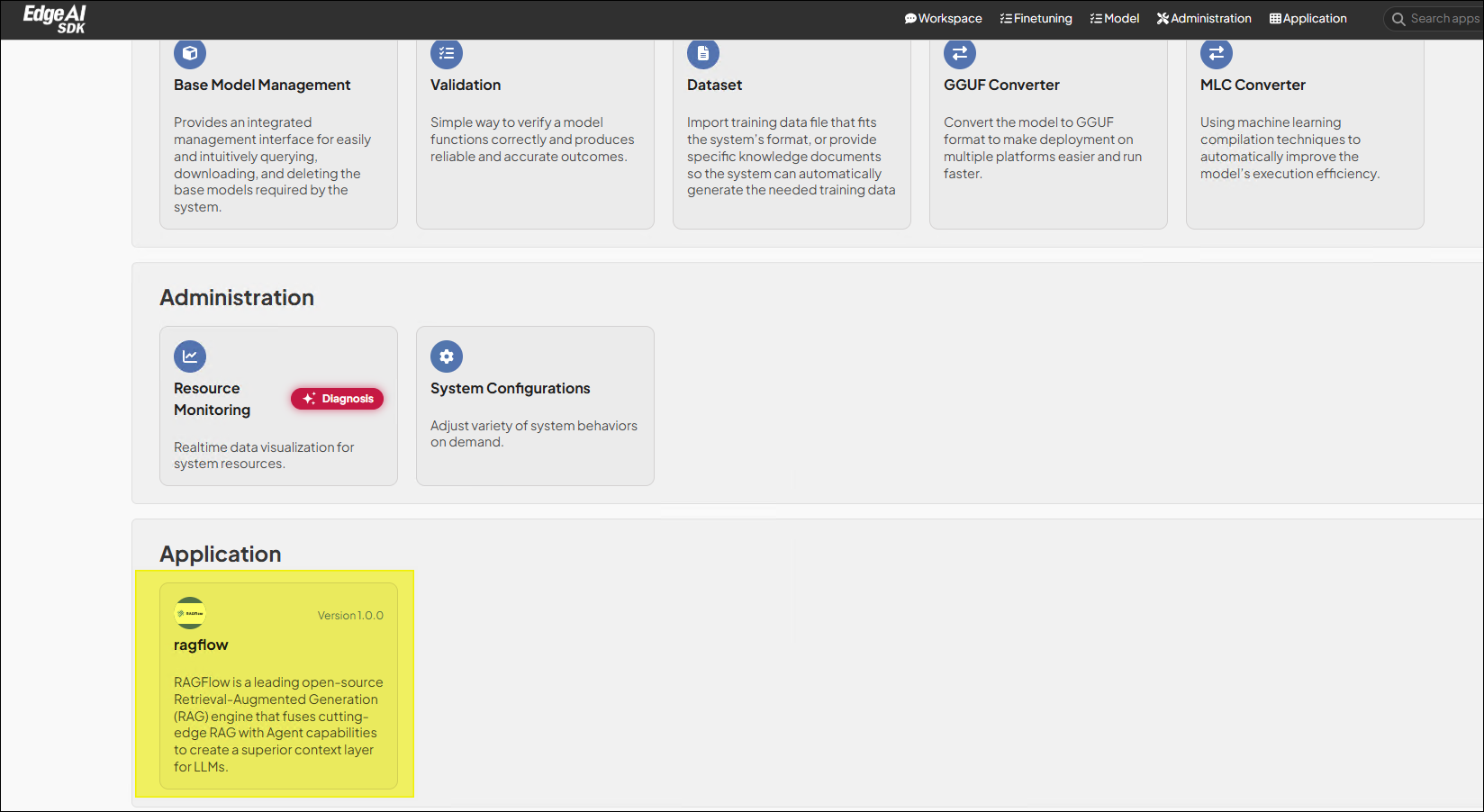
由於本應用程式初始化的時間較久,大約在 5 ~ 15 分之後,GenAI Studio 首頁中的 應用程式
類別中會多出一張代表本應用程式的功能卡,點擊該卡片即可進入 RAGFlow 應用程式。
應用程式初始化的時間會因硬體設備而異,請耐心等候。
如果您的硬體中擁有較高性能的 NVIDIA GPU,建議可以改用 GPU 模式執行本應用程式來獲取更高的性能。
只要在執行 app-up 之後加上參數 -gpu 即可將本應用程式以 GPU 模式執行。
設定 LLM
身為一個 RAG 的功能引擎,應用程式的後端亦需要一個大語言模型來充當大腦,才能提供相關功能。
-
初次進入應用程式主頁面之後,點擊 ✚ 建立知識庫。
-
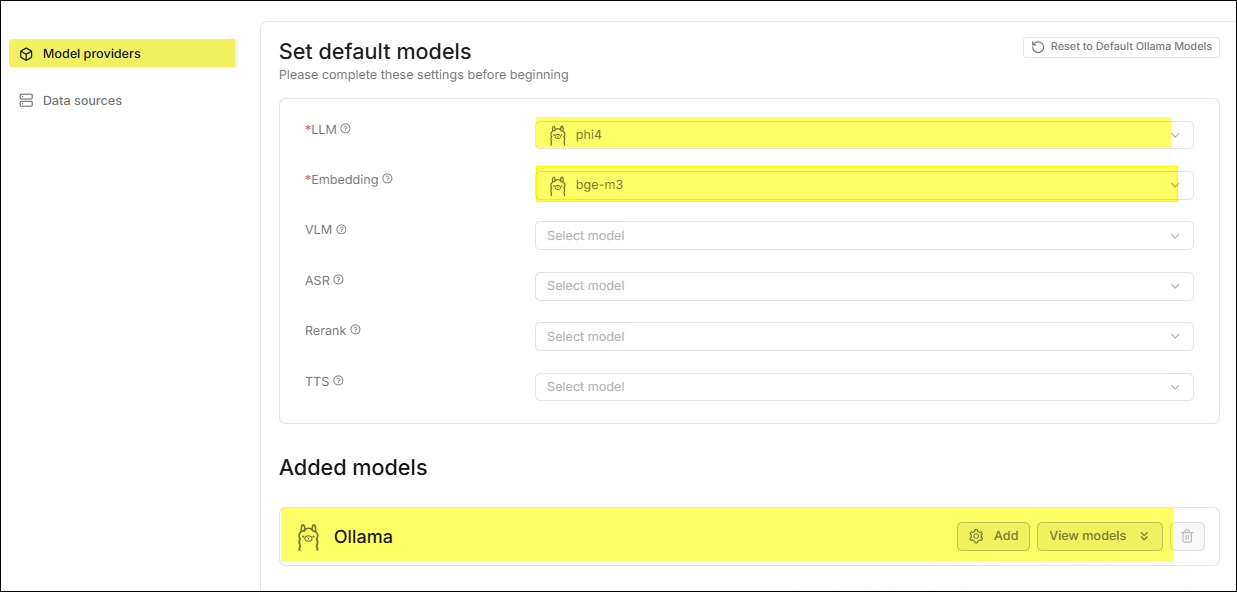
此時,由於系統尚未設定 LLM 與 Embedding 模型,系統會自動彈出警告視窗,按下 OK 按鈕。

-
系統自動跳轉至設定頁面並自動將 GenAI Studio 中 Ollama 所使用的模型同步過來。
建立第一個專屬知識庫
-
在頁面上方的橫向選單中按下 知識庫 後,點擊 ✚ 建立知識庫。
-
建立知識庫
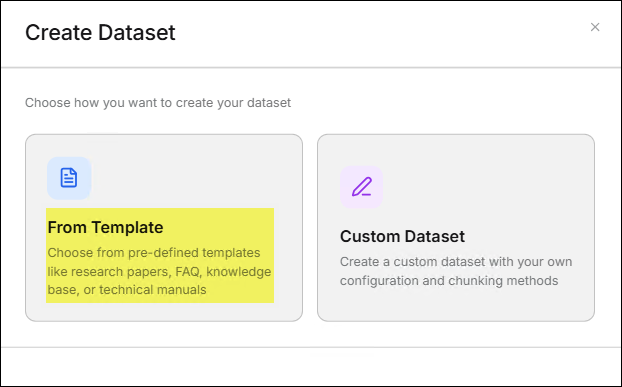
應用程式提供了二種方式讓使用者建立知識庫。- 從模版建立
- 點擊 從模版建立 功能卡。
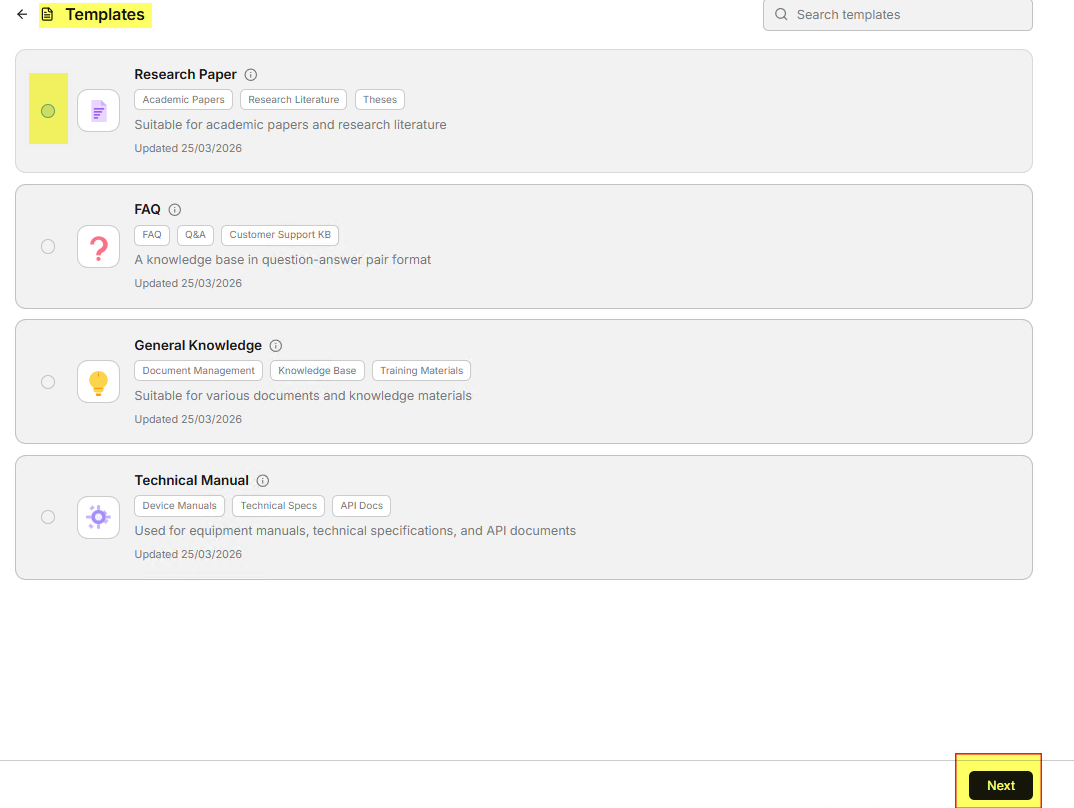
- 從模版列表中選擇最符合您需求的模版,再按下 下一步。
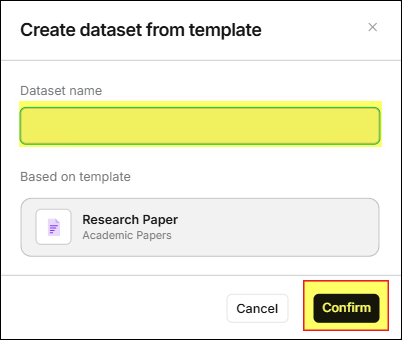
- 在 從模版建立知識庫 視窗中,輸入 知識庫名稱 並按下 確認 鈕,
頁面會跳轉至 檔案列表。
- 點擊 從模版建立 功能卡。
- 自訂知識庫
- 點擊 自訂知識庫 功能卡。
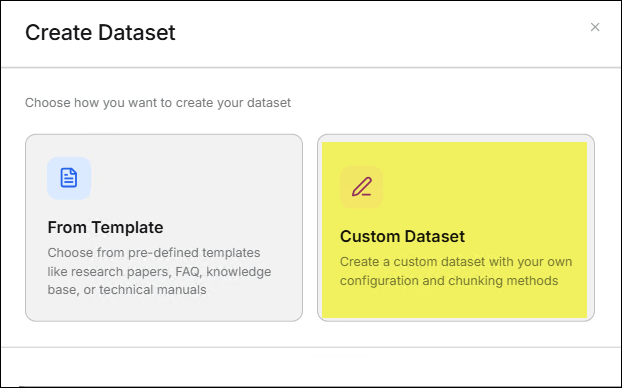
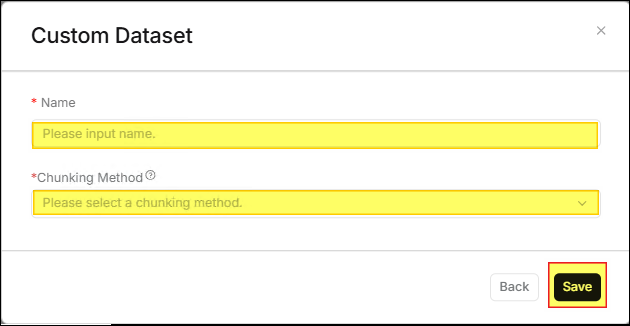
- 在 自訂知識庫 視窗中,輸入 名稱 與 分塊方法,再按下 儲存 鍵,
頁面會跳轉至 檔案列表。
- 點擊 自訂知識庫 功能卡。
- 從模版建立
-
上傳文件
進入 檔案列表 之後,點擊 上傳檔案 來開啟 上傳檔案 的視窗, 將您要上傳的文件拖曳到視窗中央來完成上傳動作。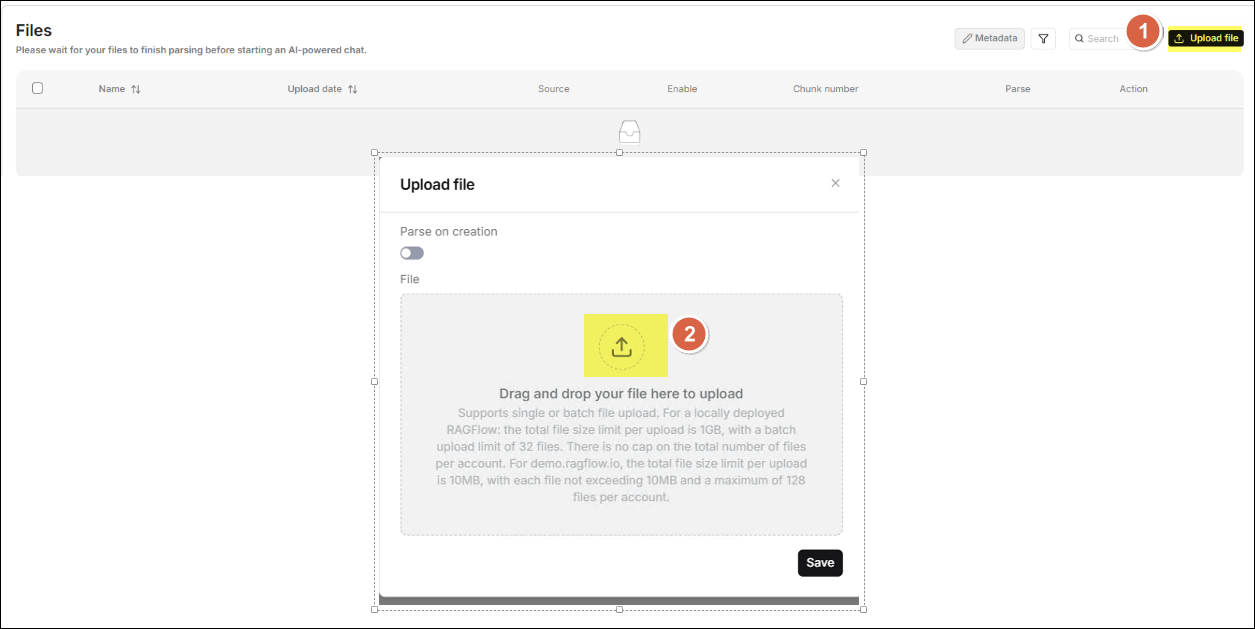
-
在 檔案列表 中會顯示您剛剛上傳的文件,點擊文件對應的 ▶️ 按鈕來開始解析文件。

-
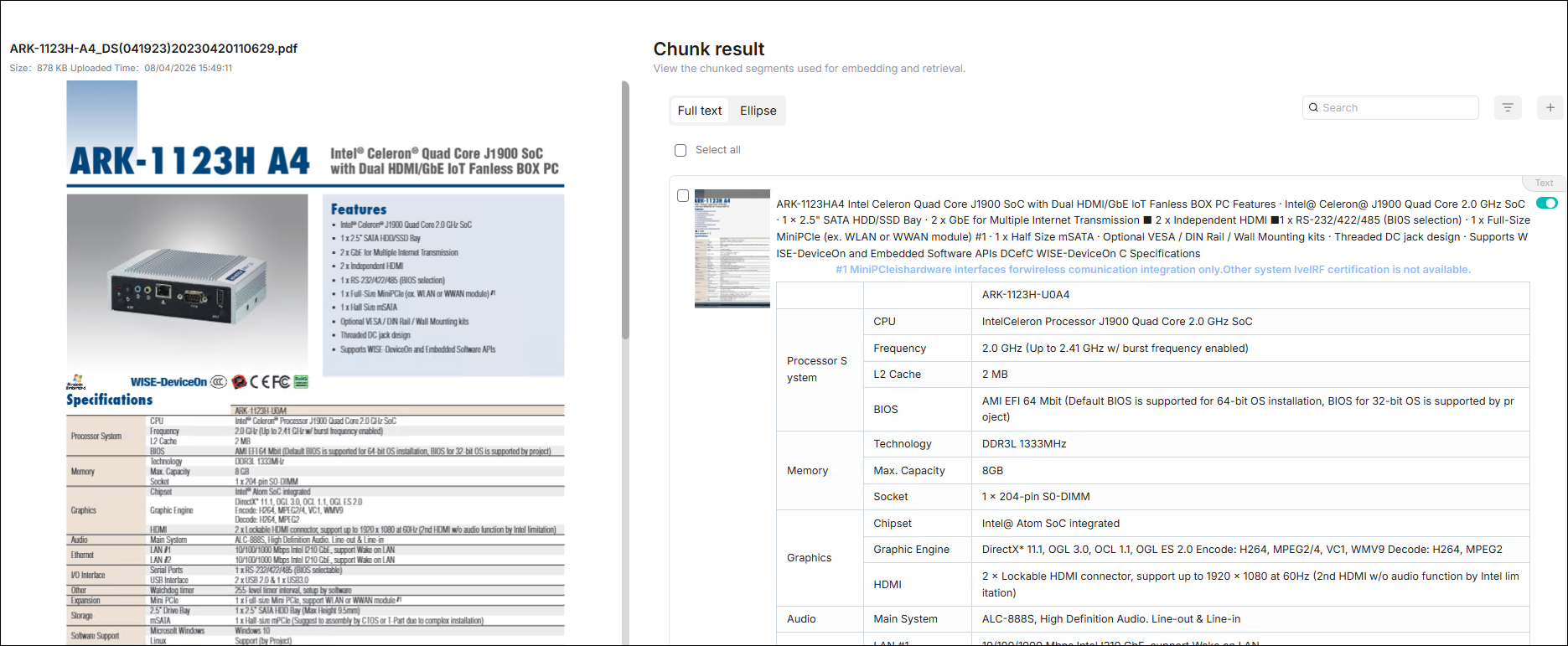
點選文件並查看解析結果。
-
點選側邊欄中的 檢索測試 頁面上進行提問,以確認您的知識庫設定是否符合預期。
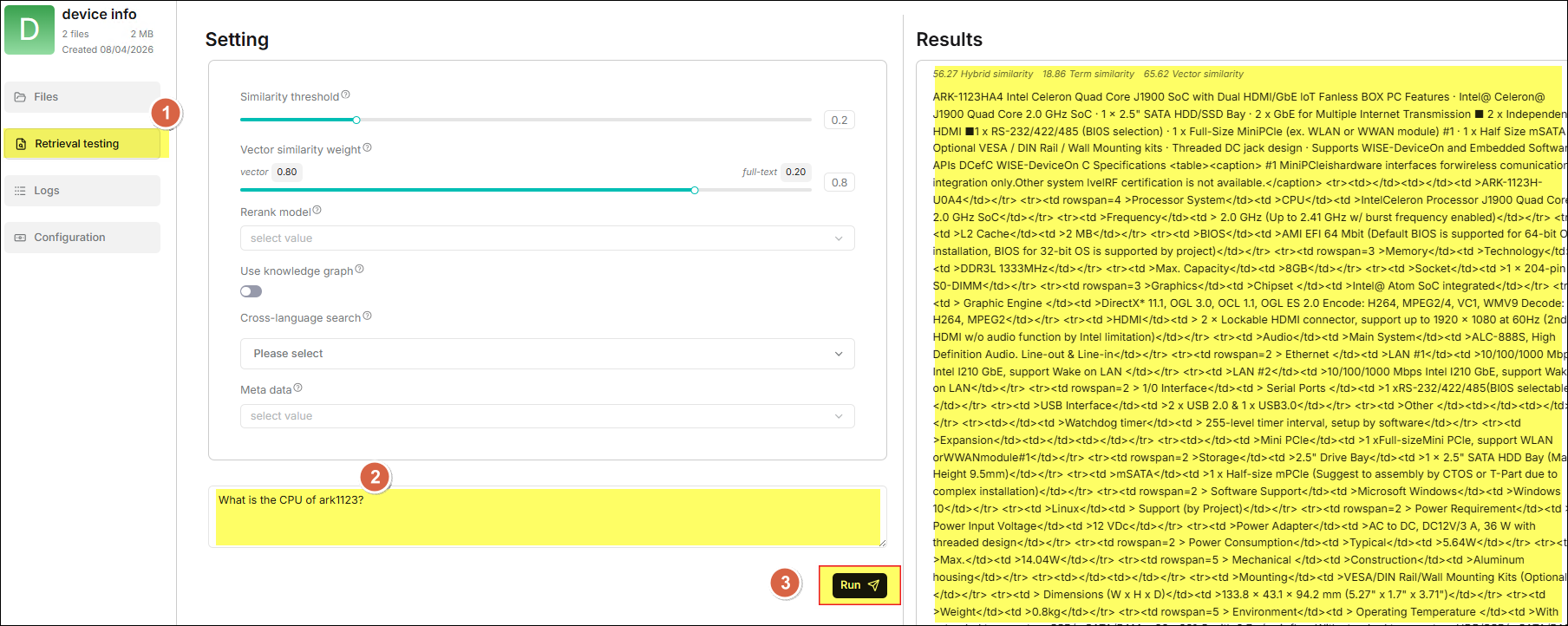
建立第一個聊天助手
-
在頁面上方的橫向選單中按下 聊天 後,點擊下方功能卡的 ✚。
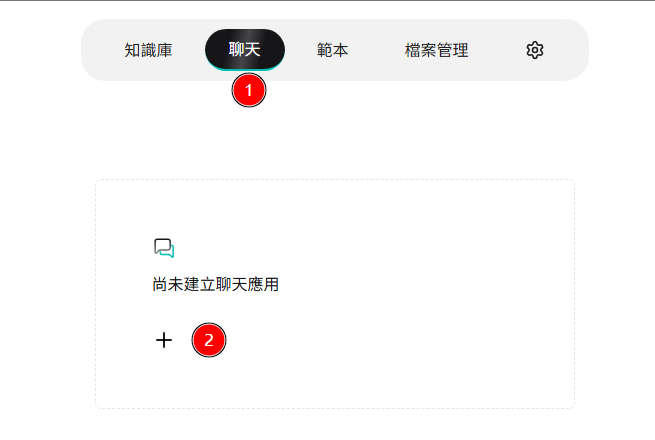
-
在開啟的 新建聊天 視窗中,輸入您要使用的名稱,再選擇該聊天室要使用的 知識庫, 按下 儲存 鍵。
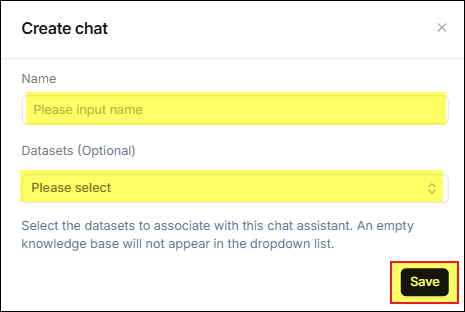
-
在 聊天 列表中會顯示一張功能卡對應剛剛建立的聊天室,點擊該功能卡來進入聊天室。 若有需要,按下頁面左下方 聊天設置 來根據實際需求進行更細部的設定。

下圖示範一個實際的使用案例。
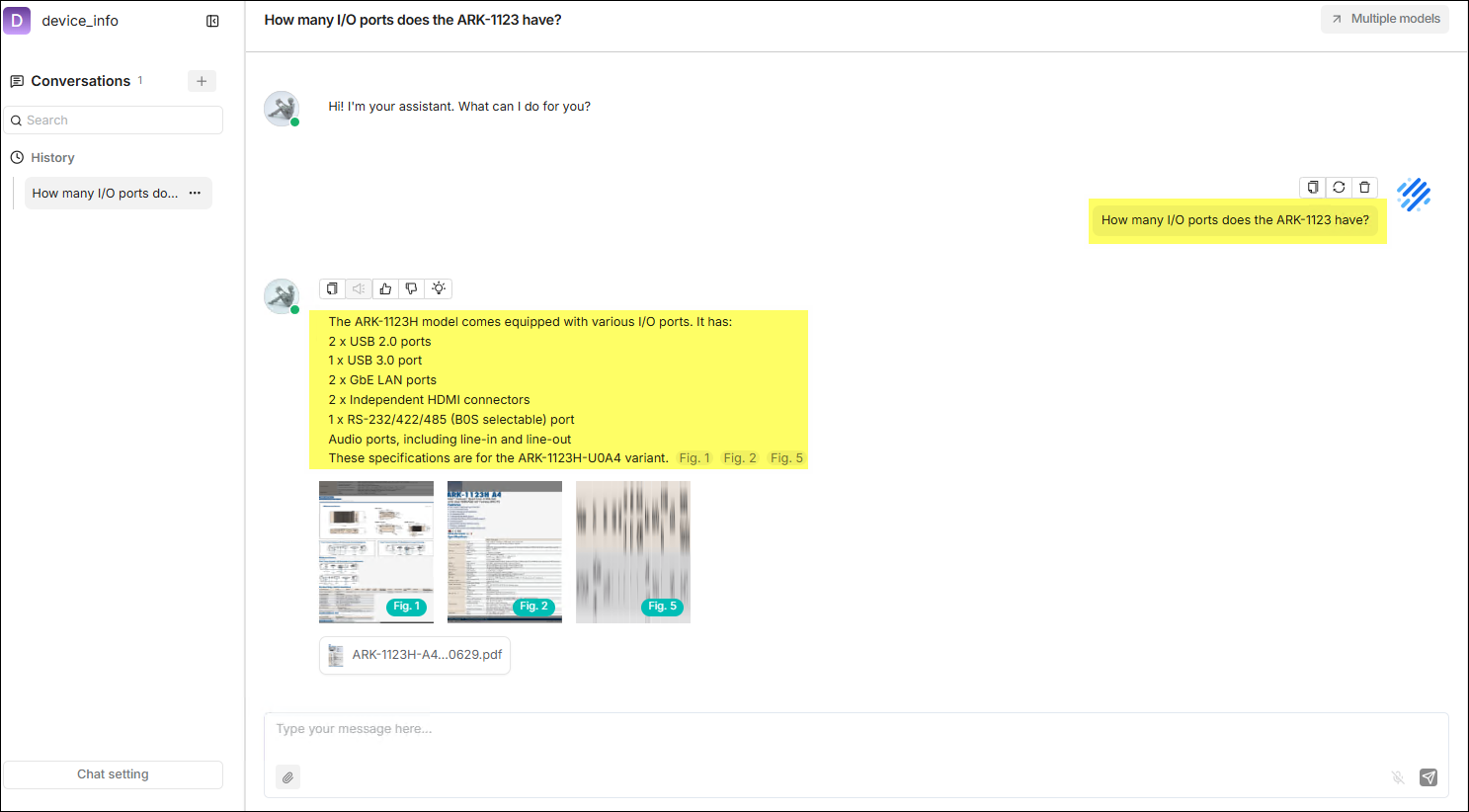
使用者指南
知識庫
知識庫是 RAGFlow 的核心數據容器。每個知識庫可包含多份文件,文件上傳後經過自動解析、
切片和向量化處理,最終可被智慧檢索與問答引用。知識庫列表如下所示:

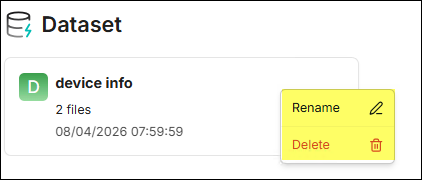
點擊知識庫卡片右側的「···」選單,可執行 重新命名 或 刪除 功能。
⚙️ 側邊欄 > 檔案列表
進入知識庫後,側邊欄中的 檔案列表 是管理知識庫內文件的主要頁面,支援多種格式文件的上傳、
解析狀態追蹤和基礎管理。要對檔案進行相關操作有二種方式,如下圖所示:

-
選取要操作檔案左方的核取方塊來顯示批次操作功能。
- 啟用: 啟用選中的檔案,使其參與檢索。
- 禁用: 停用選中的檔案,將其從檢索範圍中排除。
- 解析: 對選中的檔案觸發解析任務,生成內容切片。
- 取消: 取消正在進行中的解析任務。
- 刪除: 永久刪除選中的檔案,操作不可撤銷。
-
將滑鼠滑過檔案列表中的檔案,在該檔案所在列的右方會顯示可操作的 動作 按鈕。
- 編輯: 圖示為
 ,用來重新命名檔案名稱。
,用來重新命名檔案名稱。 - 檢視: 圖示為
 ,用來檢視該檔案的相關資訊。
,用來檢視該檔案的相關資訊。 - 下載: 圖示為
 ,用來下載該檔案。
,用來下載該檔案。 - 刪除: 圖示為
 ,用來刪除該檔案。
,用來刪除該檔案。
- 編輯: 圖示為
⛭ 上傳檔案 ⛭
支援兩種管理方式:檔案參照 與 檔案上傳。
-
檔案參照: 檔案系統支援將同一個檔案讓多個資料集進行參照。在此模式下,各資料集僅保存對檔案的「引用」, 不會重覆執行內容的複製。因此,當來源檔案發生變化時,所有引用該檔案的資料集都會同步得到更新。 適用於多個資料集需要引用同一份檔案,且希望保持內容一致的場景。
-
檔案上傳: 支援從本機上傳檔案或資料夾到資料集中。上傳後,系統會在該資料集中保存一份 獨立的檔案副本,這意味著該檔案與原始來源或其他資料集中的檔案相互獨立,互不影響。 即使原檔案被修改或刪除,當前資料集中的檔案內容也不會發生變化。適用於需要數據隔離、 版本獨立或避免相互影響的場景。
請注意雖然直接將檔案上傳到資料集似乎更方便,但我們強烈建議您先將檔案上傳到 RAGFlow 的檔案系統, 然後再將其連結到目標資料集。這樣可以避免永久刪除已上傳到資料集的檔案。
⛭ 解析檔案 ⛭
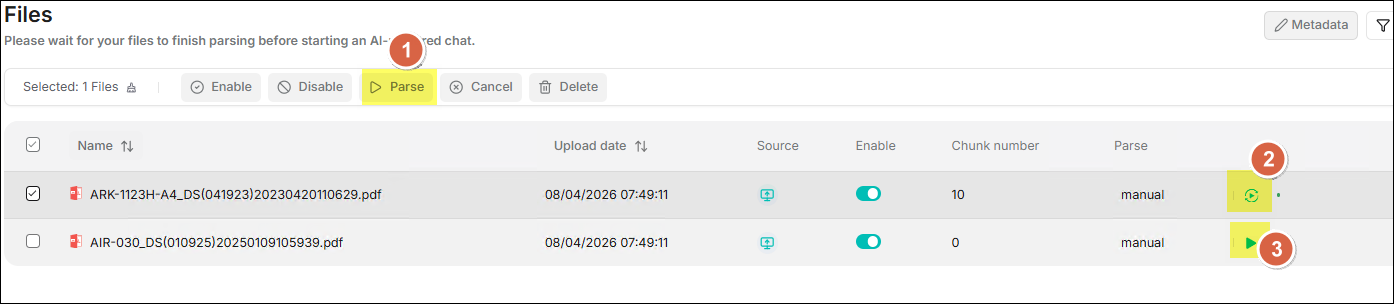 提供三種解析檔案的方法:
提供三種解析檔案的方法:
- 批量解析: 勾選一或多個檔案後,點擊上方工具列中的 解析 按鈕,對所選檔案啟動批次解析任務。
- 重新解析: 點擊位於檔案右側的旋轉圖示可對該單一檔案重新解析。
- 單一檔案解析: 點擊位於該檔案右側的播放圖示可對該單一檔案進行初次解析。
⛭ 切片結果 ⛭
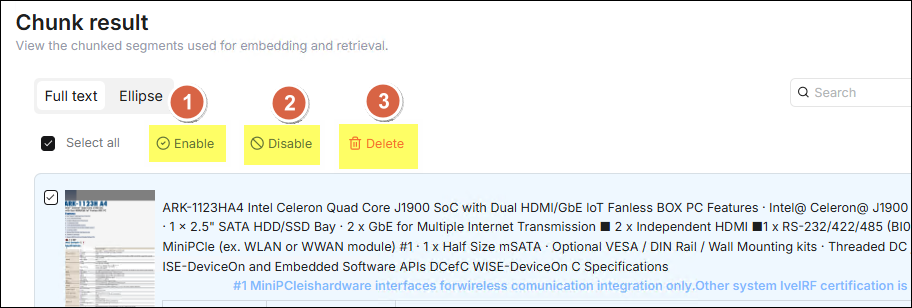 切片解析完成後,點擊該文件,可預覽該文件的切片結果,確認品質。在想操作的切片列上勾選左方的核取方塊,
即可對勾選的切片資料進行相關操作:
切片解析完成後,點擊該文件,可預覽該文件的切片結果,確認品質。在想操作的切片列上勾選左方的核取方塊,
即可對勾選的切片資料進行相關操作:
- 啟用: 啟用選中的切片,被啟用的切片將參與向量化和檢索,是正常檢索的前提條件。
- 禁用: 停用選中的切片,被停用的切片將從檢索中排除,適用於過濾無效、重複或低品質的分塊內容。
- 刪除: 永久刪除選中的切片,此操作無法回復,請謹慎使用。
⛭ 編輯切片 ⛭
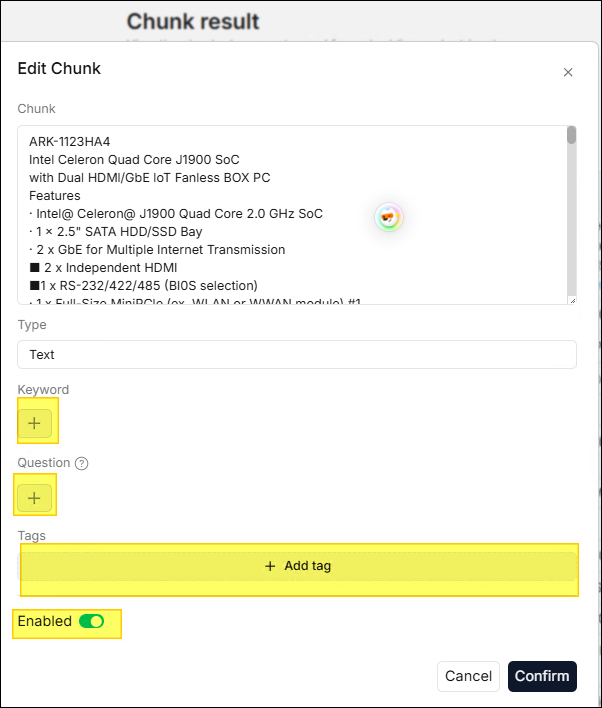
以滑鼠雙擊要編輯的切片文字,即可開啟編輯視窗,在編輯視窗中可視需要編輯 關鍵詞、問題、
標籤。
⚙️ 側邊欄 > 檢索測試
檔案上傳並解析完成後,建議在配置聊天助手前先進行檢索測試。檢索測試階段,系統會基於您指定的分塊方法, 對已產生的分塊執行混合搜尋。混合搜尋會組合「加權關鍵字相似度」與另一類語義相關分數,具體如下:
- 未選擇重排序模型時
加權關鍵字相似度 + 加權向量餘弦相似度。 - 選擇重排序模型時
加權關鍵字相似度 + 加權重排序分數。
建議準備 5-10 個代表性測試問題,涵蓋主要的使用場景,系統評估命中率後再上線聊天助手。
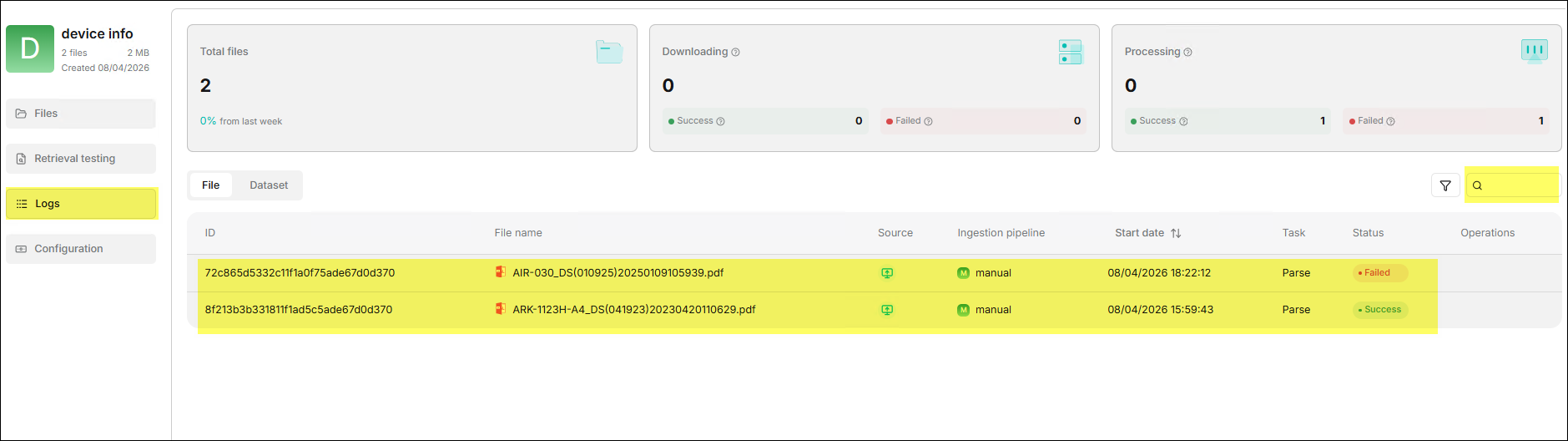
⚙️ 側邊欄 > 日誌
日誌 功能記錄該知識庫被聊天助手調用的詳細日誌,幫助管理員追蹤真實使用中的檢索行為。
⚙️ 側邊欄 > 配置
配置 是知識庫最關鍵的設定中心,直接決定文件的解析品質和檢索效果,建議在首次上傳文件前完成配置。 以下對相關設定的參數進行說明:
⛭ 基礎資訊 ⛭
| 欄位 | 是否必填 | 說明 |
|---|---|---|
| 名稱 | 是 | 範本名稱,用於在範本列表中展示與檢索。 |
| 頭像 | 否 | 範本頭像/圖示,便於在列表中快速識別。 |
| 描述 | 否 | 範本用途說明,建議描述適用文件類型與目標場景。 |
| 嵌入模型 | 是 | 該範本預設使用的嵌入模型,影響向量化品質與檢索效果。 |
| 頁面排名 | 否 | 頁面排序權重,用於控制範本在列表中的展示順序 (值越大排越前面)。 |
| 標籤集 | 否 | 範本標籤集合,用於分類、篩選與批次管理範本。 |
⛭ Ingestion pipeline ⛭
| 欄位 | 是否必填 | 說明 |
|---|---|---|
| 解析方法 | 是 | 解析類型,用於指定分塊與解析流程的實作方式。 |
| Chunking Method | 是 | 分塊方法。決定文件如何切分為可檢索的文字塊。 |
| PDF 解析器 | 否 | PDF 解析器。用於處理 PDF 文件結構與內容擷取。 |
| 自動元資料 | 否 | 元數據自動擷取開關。開啟後可進入 Settings 配置元數據提取規則。 |
| 自動關鍵詞提取 | 否 | 自動產生關鍵字數量或強度參數。值越高,自動生成的關鍵字越多。 |
| 自動問題提取 | 否 | 自動產生問題數量或強度參數。值越高,自動生成的問題越多。 |
以下對 Chunking Method 欄位中的可選項進行說明:
| 選項名稱 | 說明 | 支援檔案類型 |
|---|---|---|
| General | 按預設的 chunk token 數量對檔案進行連續分塊。 | MD, MDX, DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
| Q&A | 檢索相關資訊並生成答案以響應問題。 | XLSX, XLS (Excel 97-2003), CSV/TXT |
| Resume | 企業版專屬功能,也可在 cloud.ragflow.io 上體驗。 | DOCX, PDF, TXT |
| Manual | ||
| Table | 使用 TSI 技術進行高效數據解析的表格模式。 | XLSX, XLS (Excel 97-2003), CSV/TXT |
| Paper | ||
| Book | DOCX, PDF, TXT | |
| Laws | DOCX, PDF, TXT | |
| Presentation | PDF, PPTX | |
| One | 每份文件即為一個分塊,不進行拆分。 | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
| Tag | 該資料集作為其他資料集的標籤集使用。 | XLSX, CSV/TXT |
⛭ 全域索引 ⛭
| 欄位 | 是否必填 | 說明 |
|---|---|---|
| 索引模型 | 是 | 全域索引模型,用於知識圖譜擷取與索引建置。 |
| 提取知識圖譜 | 否 | 知識圖譜生成狀態,未生成時顯示 Not generated。 |
| 實體類型 | 是 | 實體類型集合,定義擷取目標實體類別,支援 新增/刪除。 |
| 方法 | 否 | 圖譜建置方法,影響索引建置速度與效果。 |
| 實體歸一化 | 否 | 實體消歧開關。開啟後合併同名/同義實體,減少重複實體。 |
| 社區報告生成 | 否 | 社群報告開關。開啟後可生成社群級摘要/分析結果。 |
| 使用召回增強 RAPTOR 策略 | 否 | RAPTOR 生成狀態。未生成時顯示 Not generated。 |
| 生成範圍 | 是 | 生成範圍,按整個資料集或按單一檔案生成。 |
| 提示詞 | 否 | RAPTOR 摘要提示詞範本,用於約束摘要內容和風格。 |
| 最大 token 數 | 否 | 摘要生成最大輸出 token。值越大,摘要可越長。 |
| 閾值 | 否 | 聚類閾值參數,影響聚類細粒度。 |
| 最大聚類數 | 否 | 最大聚類數上限,用於控制聚類規模。 |
| 隨機種子 | 否 | 隨機種子,用於提升生成結果的可重現性。 |
聊天
聊天 模組是使用者日常與知識庫互動的主要介面。每個聊天助手關連一個或多個知識庫, 使用者透過自然語言提問,系統基於 RAG 流程檢索知識庫並由 LLM 生成答案,同時附帶來源參照。
⚙️ 新建聊天助手
一個聊天助手代表一個特定的問答場景 (如「人事政策助手」、「產品手冊助手」),不同助手可綁定不同知識庫和模型配置。
- 進入聊天模組: 點擊頁面頂端中間選單的 聊天,進入聊天助手列表頁。
- 新建助手: 點擊 ✚ 按鈕,彈出 新建聊天 對話框。
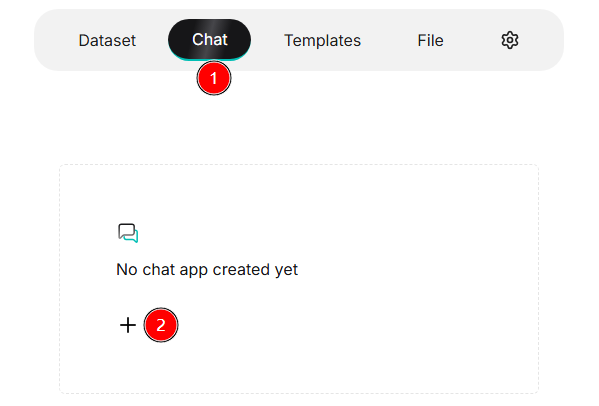
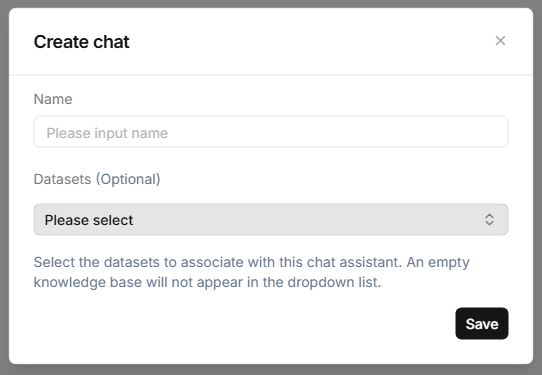
- 填寫資訊: 輸入 名稱 並選擇 知識庫。
- 儲存並啟用: 完成後點擊 儲存,助手出現在聊天列表中,點擊即可開始對話。
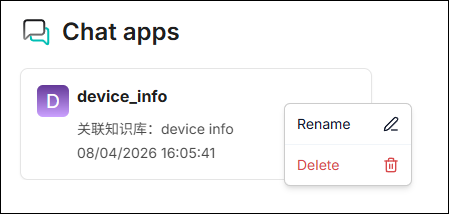
⚙️ 聊天管理
點擊聊天卡片右側的「···」選單,可執行 重新命名 或 刪除 功能。
⚙️ 聊天設定
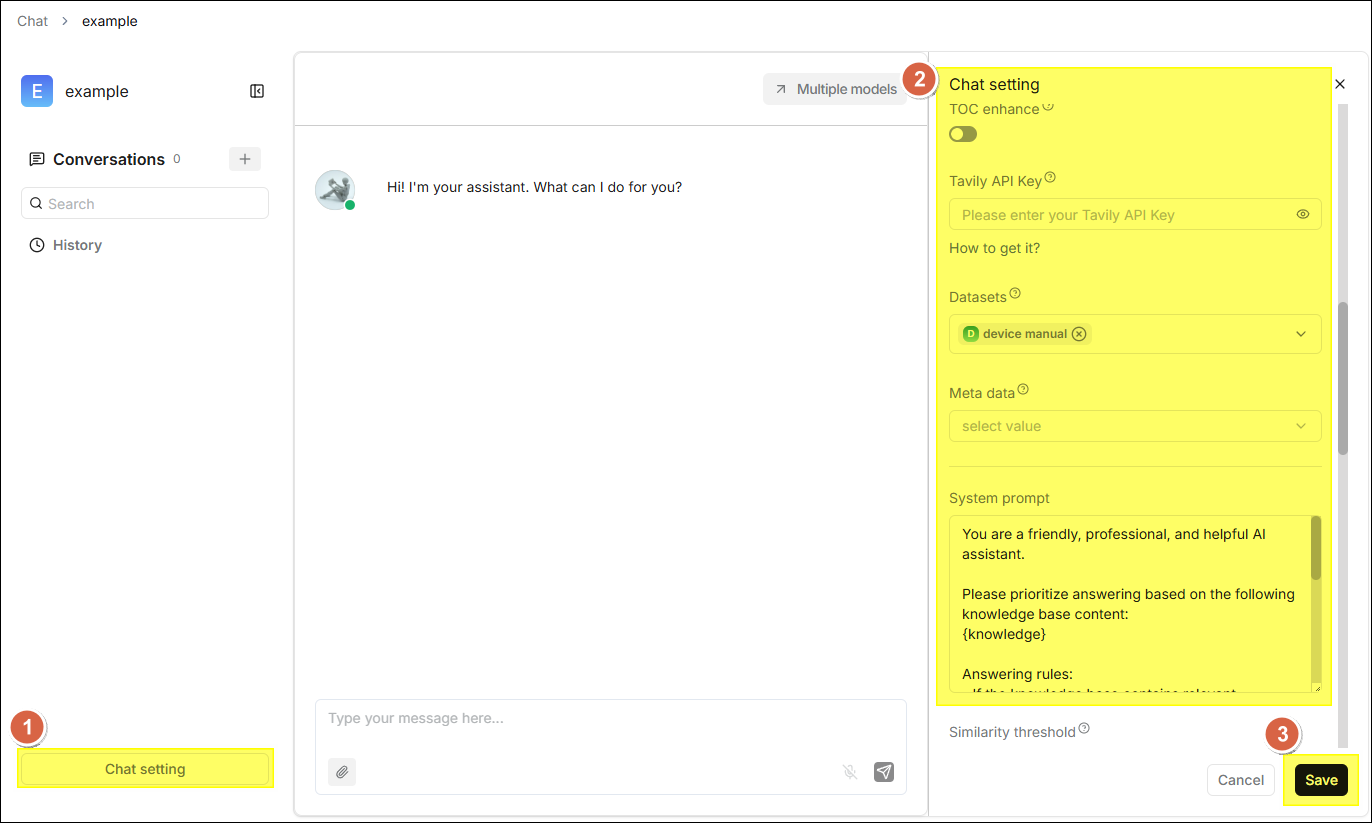
點擊聊天卡片進入聊天主頁面後,可以點擊左側下方的 聊天設置,詳細配置會出現在頁面右側, 可調整以下設定:
| 欄位 | 說明 |
|---|---|
| 助理頭像 | 設定聊天助手的頭像圖示,顯示在對話介面中。 |
| 助理姓名 | 聊天助手的顯示名稱。 |
| 助理描述 | 對該助手用途的簡要說明,幫助使用者了解助手的適用場景。 |
| 空回覆 | 知識庫中未檢索到相關內容時的固定回覆。若留空,LLM 將根據自身知識回答,此種情況下可能產生幻覺。 |
| 設定開場白 | 對話開始時助手向使用者展示的歡迎語。 |
| 顯示引文 | 開啟後在回覆中展示所引用的原始文件片段及來源,增強答案可信度。 |
| 關鍵詞分析 | 啟用後由 LLM 對使用者問題進行關鍵字擷取,強化相關性計算。 |
| 文字轉語音 | 開啟後將回覆內容轉為語音播放;需提前配置 TTS 模型。 |
| 目錄增強 | 解析過程中生成文件目錄資訊時,啟用此項可優化檢索邏輯。 |
| Tavily API Key | 填入 API Key 後,系統將在知識庫檢索基礎上疊加 Tavily 網路搜尋。 |
| 知識庫 | 選擇關聯的知識庫,支援多選。 |
| 系統提示詞 | 定義助手角色、回答範圍和語氣。注意: {knowledge} 為預先定義的變數。 |
| 相似度閾值 | 混合相似度的過濾閾值 (0-1)。低於此閾值的文字塊將被捨棄。 |
| 向量相似度權重 | 混合相似度中向量餘弦相似度所佔的權重。 |
| Top N | 超過相似度閾值時,僅將排名前 N 個的結果作為上下文。 |
| 多輪對話優化 | 多輪對話時根據上下文對查詢問題進行改寫優化,提升檢索準確率。 |
| 使用知識圖譜 | 開啟後檢索對應的知識圖譜,適合處理複雜多跳問題;會顯著延長檢索時間。 |
| 推理 | 啟用推理工作流,增強多步驟邏輯推理的能力。 |
| Rerank 模型 | 對初步檢索結果進行二次評分排序,提升召回品質。 |
| 跨語言搜尋 | 選擇目標語言,系統將翻譯查詢後執行跨語言檢索。 |
| 變數 | 動態調整系統提示詞的變數設定。 |
| 模型 | 選擇用於生成回覆的大語言模型(必填)。 |
| 自由度 | 預設「精確」、「平衡」、「即興」、「自定義」四種模式。 |
| 溫度 | 控制輸出的隨機性;值越低回答越保守,值越高越具創造性。 |
| Top P | 核採樣參數,建議保持預設值 0.3。 |
| 存在懲罰 | 防止模型重複相同內容。 |
| 頻率懲罰 | 減少模型頻繁重複相同詞彙的傾向。 |
| 最大 token 數 | 單次回覆允許輸出的最大 Token 數。 |
空回覆 配置非常重要。不設定時,當知識庫無命中內容,LLM 可能憑自身知識「編造」答案。 建議明確配置此選項以確保回覆可靠性。
⚙️ 對話歷史管理
系統自動儲存同一聊天助手內的所有對話工作階段 (session),方便隨時查看和繼續之前的對話:
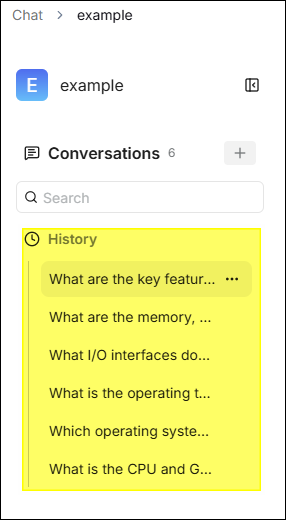
- 歷史會話列表: 進入聊天助手後,左側邊欄展示該助手的歷史會話列表,按時間倒序排列。
- 繼續對話: 點擊歷史會話可重新載入完整對話上下文,在此基礎上繼續追問。
- 新建會話: 點擊 對話 右側 ✚ 開始全新對話,不受歷史上下文影響。
- 刪除會話: 滑鼠懸停在會話標題上,點擊右側「...」標識,再點擊垃圾桶圖示刪除。
⚙️ 多模型
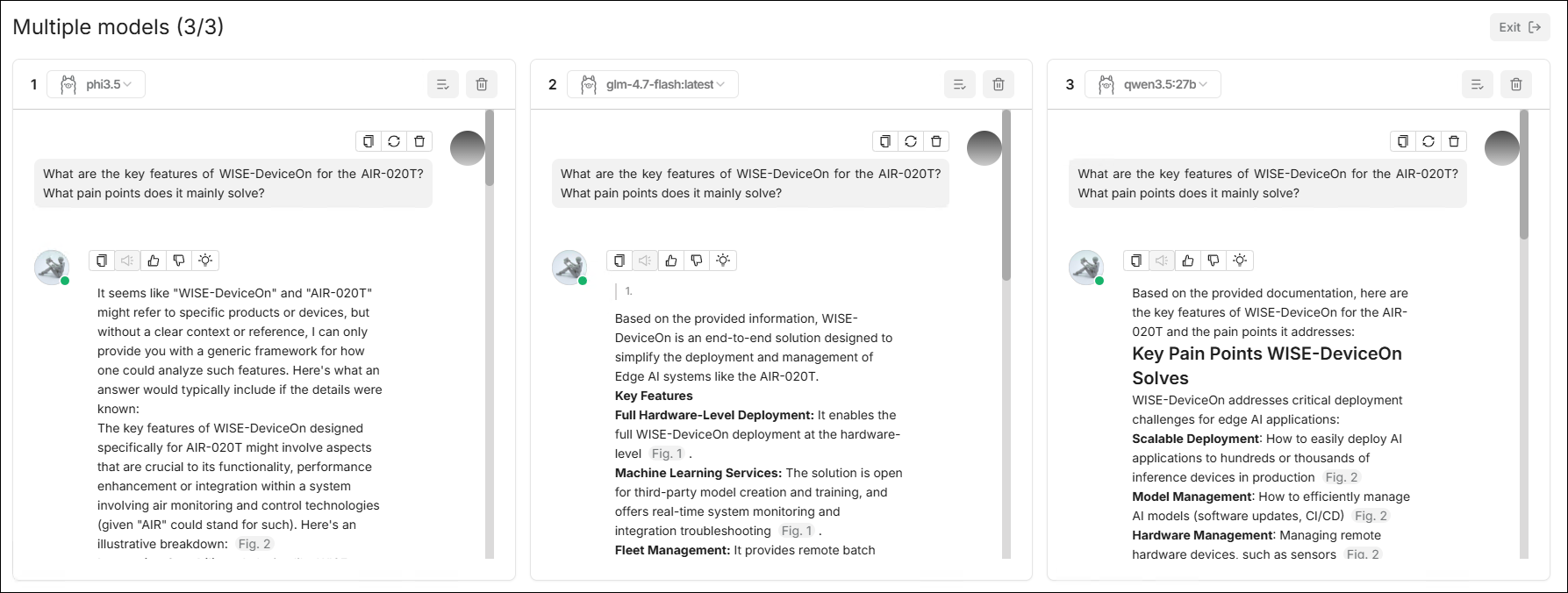
當使用者需要對同一個問題從多個模型同時獲取回答並進行橫向比較時,可使用 多模型管理 功能。 該功能支援在同一介面中並行最多配置 3 個模型會話窗格,每個窗格可獨立選擇模型並單獨展示輸出結果。
-
核心能力
- 多窗格並行對話: 一個頁面同時展示多個模型對話區域。
- 獨立模型選擇: 每個窗格可單獨切換模型。
- 窗格管理: 支援對單一窗格執行刪除等操作。
- 統一輸入區: 底部統一輸入消息,一次發送後可觀察多模型響應差異。
-
典型使用場景
- 對比不同模型在同一專業問題上的回答品質。
- A/B 測試提示詞效果或參數設定。
- 在上線前選擇最合適的預設模型。
模版
模版 是我們研發的知識庫快捷配置功能。其核心目標是在使用者新建知識庫時,提供可直接使用的預置參數組合。
⚙️ 用途與說明
使用者進入 模版 頁面後,可看到系統內建的 4 個模版卡片:
- Research Paper
- FAQ
- General Knowledge
- Technical Manual
每個模版卡片上會顯示 模版名稱、標籤、簡要說明 與 更新時間,說明如下:
| 模版名稱 | 適用場景 | 推薦文件類型 | 特點 |
|---|---|---|---|
| Research Paper | 學術論文、研究報告解讀 | PDF(論文) | 按論文結構章節切分。 |
| FAQ | 問答庫/客服知識庫 | Excel / CSV / TXT | 針對 Q&A 結構優化。 |
| General Knowledge | 通用企業知識、培訓資料 | 多格式 | 通用型模版,應用面最廣。 |
| Technical Manual | 設備說明書、操作手冊 | PDF(手冊) | 按手冊層級與章節切分。 |
這四個模版的價值在於「開箱即用」。使用者無需理解全部底層參數,也能快速得到較好的初始檢索效果。
⚙️ 查看模版詳情
使用者可以查看每個模版的詳細說明,並根據實際需要調整參數後儲存,步驟如下:
- 進入 模版 頁面。
- 點擊任一模版卡片的右上角 ⓘ 標識,即會彈出模版的詳細資訊面板以供查看。
⚙️ 修改模版參數
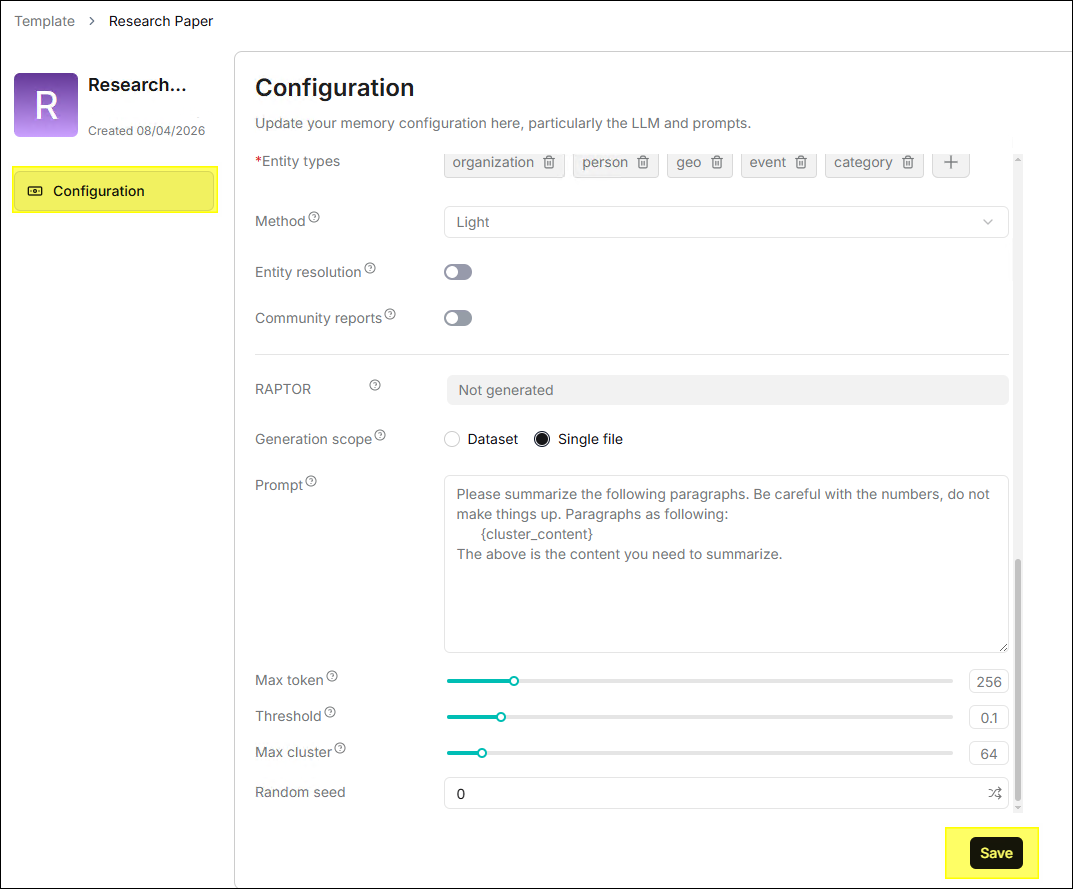
- 點擊任一模版卡片,即可打開配置頁面,調整名稱、描述、標籤、嵌入模型、解析器等參數。
- 點擊 儲存,修改後的參數立即生效。
建議先使用系統預設範本建立首個知識庫;當累積了實際問答數據後,再按命中效果逐步微調。
檔案管理
檔案管理 用於統一管理平台中的原始檔案。先上傳到檔案管理再連結到目標資料集,可顯著提升複用效率。
⚙️ 檔案管理與資料集關聯
系統支援單個或批量上傳檔案,並將已上傳檔案連結到一個或多個目標資料集。這種方式特別適合以下場景:
- 需要同一份原始檔案被多個資料集複用。
- 需要刪除某些已解析檔案,但仍保留原始檔案。
- 需要在統一目錄中進行檔案檢索、移動、重新命名。
⚙️ 建立資料夾
檔案管理支援建立巢狀資料夾結構。下面說明在根目錄建立資料夾的步驟:
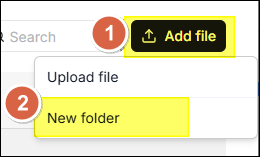
- 在檔案管理頁面點擊右上角 新增檔案。
- 在下拉選單中選擇 新建資料夾。
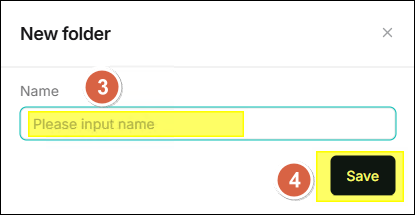
- 在對話視窗中的 名稱 欄位中輸入資料夾名稱。
- 點擊 儲存。
每個資料集在 root/.knowledgebase 下都有對應資料夾,不允許 在該資料集的資料夾內再建立子資料夾。
⚙️ 上傳檔案
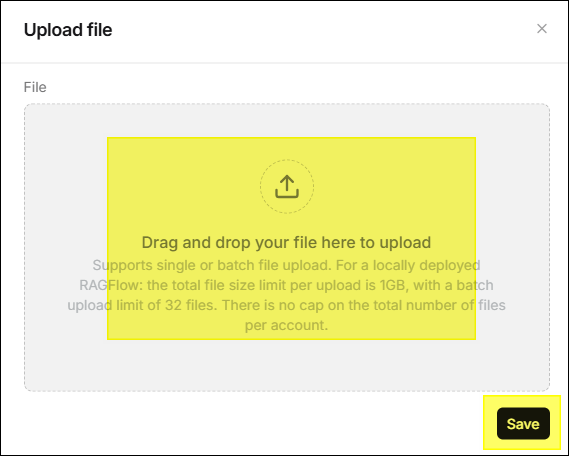
- 點擊右上角 新增檔案 > 上傳檔案。
- 在對話視窗中拖曳檔案或點擊選擇位於本地端的檔案。
- 點擊 儲存。
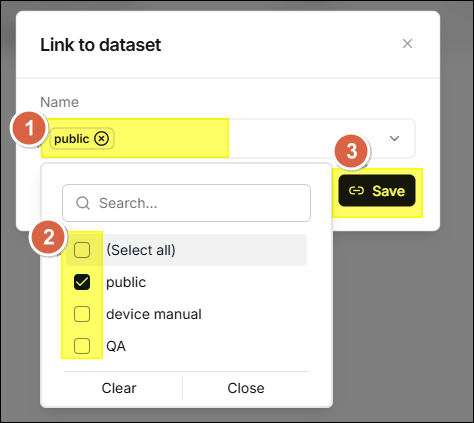
⚙️ 連結檔案到資料集
已上傳檔案可鏈結到一或多個數據集,系統會在目標數據集中創建檔案的引用。
- 將滑鼠懸停在檔案列,此時該列右方的操作區會顯示若干圖示,點擊
 圖示。
圖示。 - 選擇資料集並點擊 Save 進行連結。
- 在檔案管理中刪除該檔案時,會自動移除所有相關資料集中的引用。
⚙️ 預覽檔案
支援線上預覽以下格式的檔案:
- DOCS
- XLSX
- JPEG
- JPG
- PNG
- TIF
- GIF
⚙️ 移動檔案到指定資料夾
支援將檔案移動至指定目錄便于管理。只要在檔案列的操作區點擊 ![]() 圖示並選擇目標資料夾即可。
圖示並選擇目標資料夾即可。

⚙️ 搜尋檔案或資料夾
搜尋框僅支援對當前目錄中的檔案名稱或資料夾名稱進行篩選。
- 不會檢索子目錄中的檔案或資料夾。
- 建議先進入目標目錄再執行關鍵字搜尋。
⚙️ 重新命名檔案或資料夾
文件管理支援對檔案及目錄重新命名。在操作區點擊 ![]() 圖示並輸入新名稱。
圖示並輸入新名稱。
⚙️ 刪除檔案或資料夾
支援單獨刪除或批量刪除。
- 單獨刪除: 在操作區中點擊 圖示。
- 批量刪除: 勾選多個檔案後統一執行刪除。
- 系統不允許刪除根目錄
root/.knowledgebase。 - 刪除已連結到資料集的檔案時,會同步移除所有資料集中的引用。
⚙️ 檔案下載
點擊 ![]() 圖示即可下載原始檔案。
圖示即可下載原始檔案。
模型配置
模型配置 用於管理各類 AI 模型(LLM、Embedding、Reranker、VLM、ASR、TTS)。
⚙️ 設定預設模型
RAGFlow 支援為不同模型類型分別設定系統預設值,新建立的知識庫和聊天助手會自動使用這些預設模型。
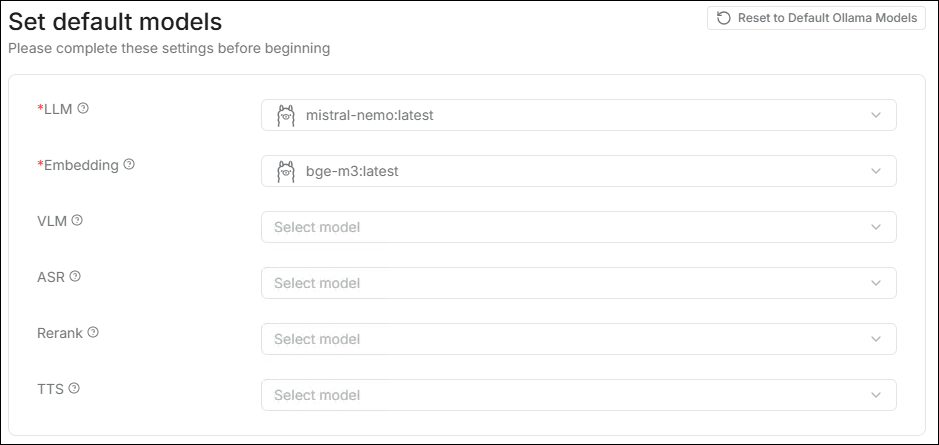
- LLM: 處理對話的主要模型。
- Embedding: 負責向量化,決定檢索準確度。
- VLM: 用於理解圖片內容。
- ASR: 語音轉文字。
- Rerank: 提升檢索排序品質。
- TTS: 文字轉語音。
如果系統中已存在資料,更換預設 Embedding 模型屬於高風險操作。 一旦確認後將清除所有已生成的向量資料並移除已上傳的檔案。
⚙️ 模型供應商
支援多種主流模型及供應商,並可通過 Ollama / LocalAI 部署本機模型。
| 供應商 | 支援類型 |
|---|---|
| OpenAI | LLM (GPT-4o、GPT-4、GPT-3.5 等)、Embedding (text-embedding-3-small/large) |
| DeepSeek | LLM (DeepSeek-V3、DeepSeek-R1 等)、Embedding |
| Qwen | LLM (Qwen-Max、Qwen-Plus 等)、Embedding (text-embedding-v3) |
| Zhipu AI | LLM (GLM-4 等)、Embedding (embedding-3) |
| Baidu | LLM (ERNIE 系列)、Embedding |
| Ollama | 所有 Ollama 管理的本地模型 (Llama 3、Qwen2、Mistral 等) |
| NVIDIA NIM | 支援 NVIDIA GPU 加速的企業级模型推理 |
| Hugging Face | 支援平台上的開源模型通過 API 介接 |
⚙️ 模型同步
- 首次進入 設定預設模型 頁面,系統會自動同步 GenAI Studio 中已拉取的 Ollama 模型。
- 若 GenAI Studio 目前使用的 LLM 和 Embedding 是由 Ollama 提供,系統會一併同步對應的 Ollama 配置。
- 點擊右上角的 重置為預設 Ollama 模型, 即可一鍵恢復為與 GenAI Studio 一致的預設配置。
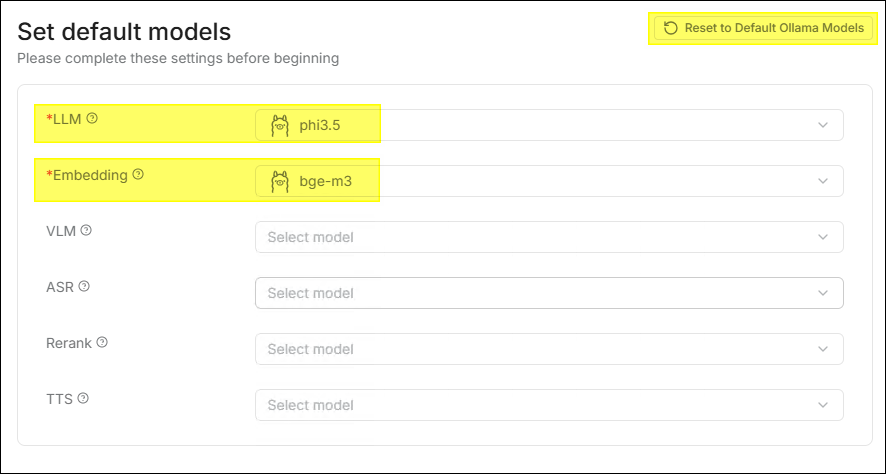
- 只有在 GenAI Studio 目前的 LLM 和 Embedding 均使用 Ollama 時,按鈕 重置為預設 Ollama 模型 才會啟用;否則該按鈕僅顯示但無法點擊。
- 若修改 Embedding 的設定並點擊 重置為預設 Ollama 模型,所有已生成的向量資料和知識庫中已上傳的檔案皆會被系統清除。
⚙️ 新增模型
- 點擊頁面上方歯輸圖示。

- 在頁面右方的供應商卡片中找到要設定的供應商 (如 OpenAI、DeepSeek 等),點擊該卡片。
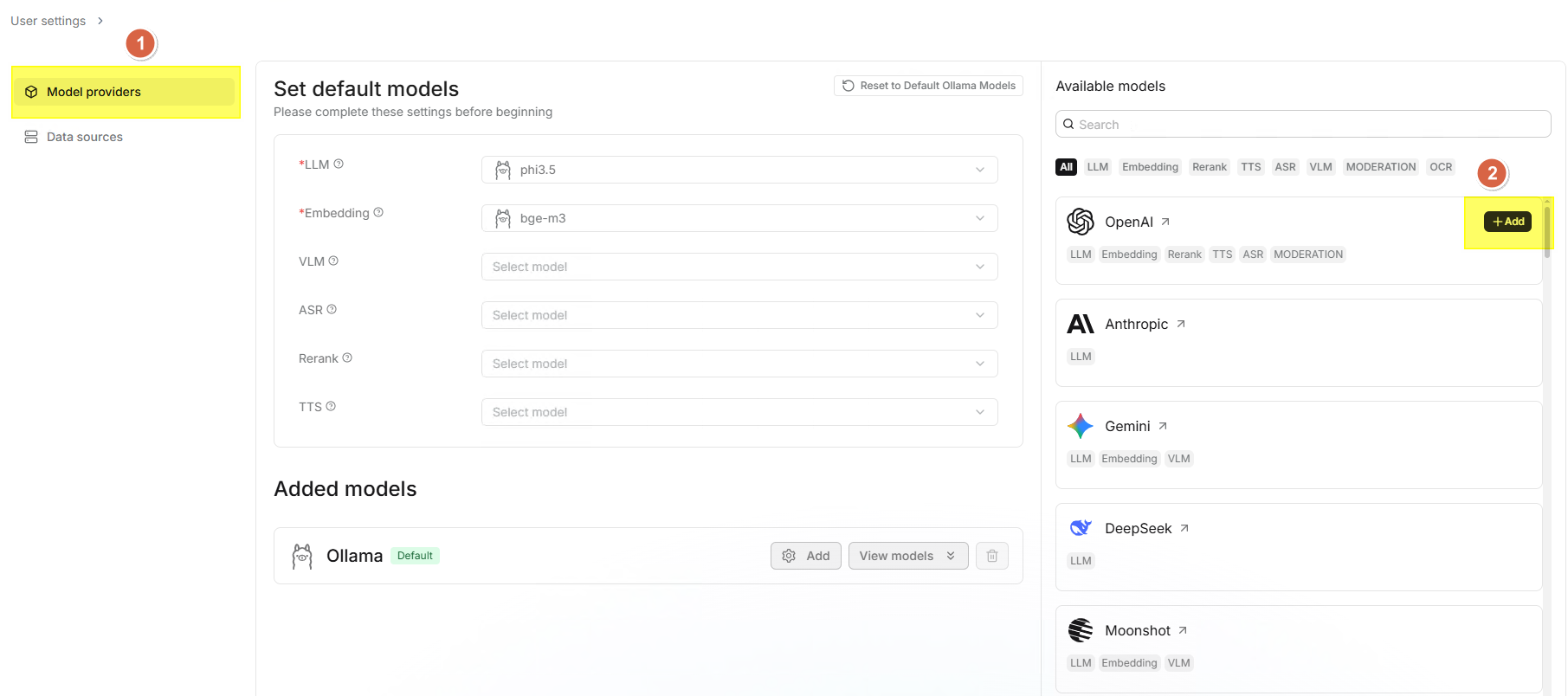
- 填入 API-Key (必填),部分供應商需填寫 Base-Url。
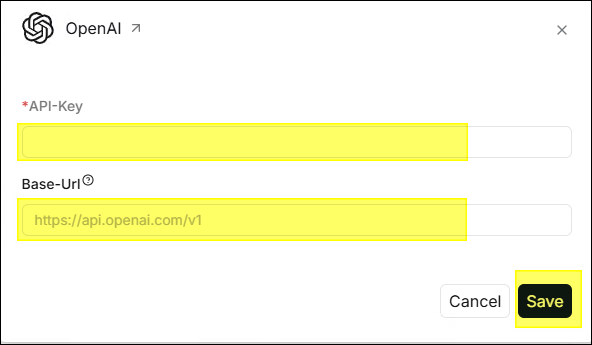
- 點擊 儲存 後,該設定會出現在下方 已添加的模型 區塊內。
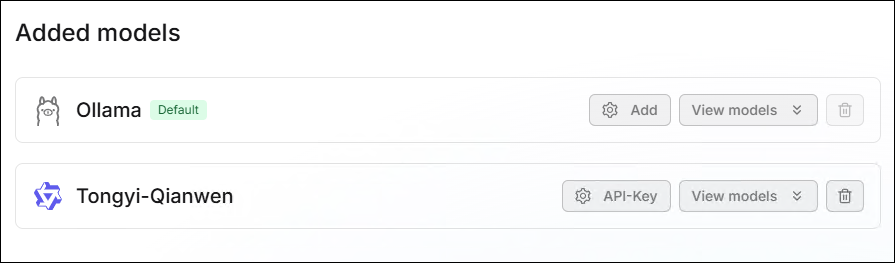
⚙️ 模型管理
在 已添加的模型 區塊內可以對模型進行管理,支援 刪除、編輯 及 啟用/停用 操作。
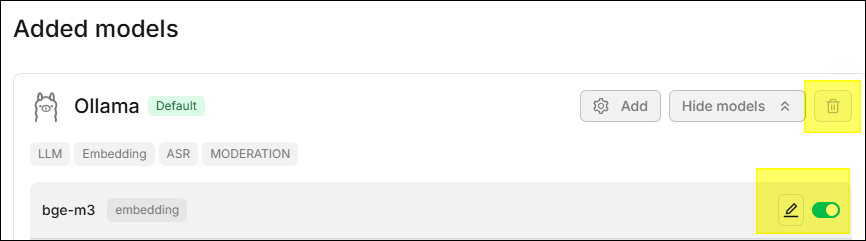
- 刪除: 點擊 圖示來進行刪除。
若該模型仍被知識庫或聊天助手使用,需先解除绑定。
- 編輯: 點擊 圖示來編輯模型設定。
- 啟用/停用: 點擊模型右方的開關,來啟用或停用該模型。
⚙️ 資料源
資料源 讓系统與企業既有的數據進行資料同步,無需再手動上傳。目前支援的資料源包括:
Confluence、Google Drive、GitHub、GitLab、Discord、Jira、WebDAV、IMAP 等。
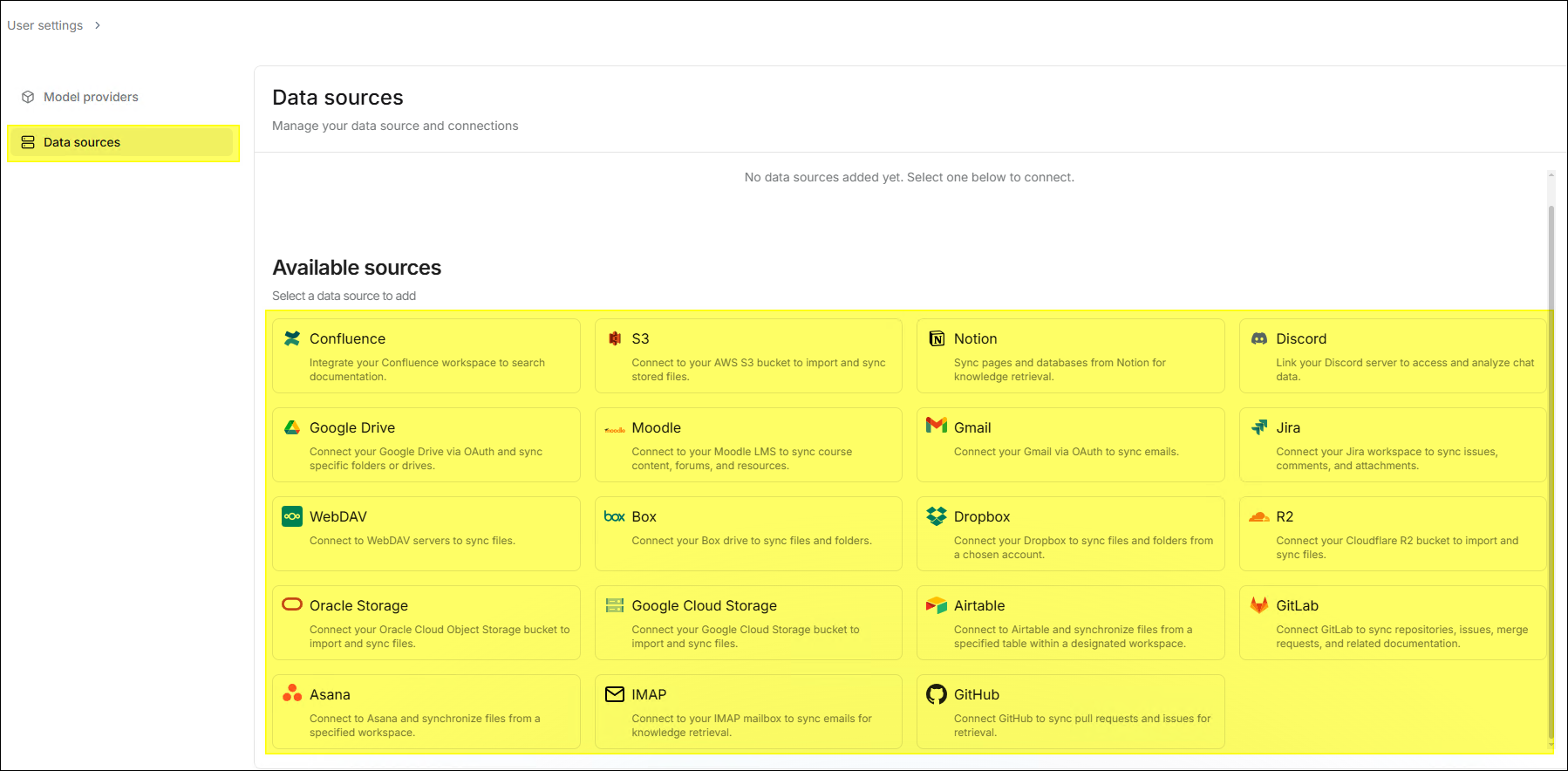
- 不同資料源所需設定的資訊不盡相同,請依照您所選擇的資料源來設定。
- 針對需要權杖才能進行訪問的資料源,強烈建議使用獨立的權杖並遵循最小權限原則。
說明
角色與權限
RAGFlow 的權限管理與 GenAI Studio 相同,支援使用者角色分級管理,並可設定不同角色的權限。
| 功能/權限 | 系統管理員 (Admin) | 管理員 (Manager) | 普通用戶 (Default) |
|---|---|---|---|
| 修改系統設定 | ️ ✔️ | ❌ | ❌ |
| 編輯系統模版 | ✔️ | ❌ | ❌ |
| 刪除系統模版 | ✔️ | ❌ | ❌ |
| 建立知識庫 | ✔️ | ✔️ | ❌ |
| 編輯知識庫設定 | ✔️ | ✔️ | ❌ |
| 檢視 (綁定) 知識庫 | ✔️ | ✔️ | ❌ |
| 刪除知識庫 | ✔️ | ✔️ | ❌ |
| 建立聊天室 | ✔️ | ✔️ | ❌ |
| 編輯聊天室設定 | ✔️ | ✔️ | ❌ |
| 檢視 (使用) 聊天室 | ✔️ | ✔️ | ✔️ |
| 刪除聊天室 | ✔️ | ✔️ | ❌ |
數據集格式
上傳結構化數據集時,請遵守下列格式與規範以確保內容解析的品質:
- CSV:
- 使用不含 BOM 的 UTF-8 编码。
- 首行必須為欄位名稱。
- 欄位名稱應避免空格和特殊字元。
- 空欄位請以空字符串表示。
- JSON:
- 最外層為 JSON 的陣列型態。
- 每個陣列元素為一個物件。
- 支援最多三層的巢狀物件。
- 欄位名稱可使用英文或不含空格的中文。
- Excel (.xlsx):
- 資料從 A1 啟始。
- 首行為欄位名稱。
- 避免合併儲存格。
- 每張表 (sheet) 單獨處理。
常見問題
如何設定不支援的 LLM ?
如果您的模型目前不被支援,但具備了與 OpenAI 相容的 API 介面,請在 模型提供商 設定面中選擇 OpenAI-API-Compatible 卡片來設定您的模型。
如何提高聊天速度 ?
請注意,某些設定可能會消耗大量時間。如果您發現聊天時模型回答問题的時間太久,請参考以下建議:
- 禁用多輪優化以减少從模型取得答案所需的時間。
- 将 重新排序模型 設定留空,能顯著降低檢索時間。
- 禁用推理可缩短模型的思考時間。對於像 Qwen3 這種模型,您還需要在系统提示中添加
/no_think相應的設定來禁用推理功能。 - 使用重排序模型時,請確保您有 GPU 可進行加速;否则,重排序過程會非常慢。
- 禁用關鍵字分析可缩短收到模型回覆的時間。
AI 搜索和聊天的主要區别是什麼 ?
- AI 搜索: 是一次單輪的 AI 對話,使用預先定義的檢索策略 (加權關鍵詞相似度和加權向量相似度的混合搜索) 以及系统的預設聊天模型。不涉及知識圖譜、自動關鍵詞或自動提問等高级 RAG 策略。檢索到的訊息會列在聊天模型的回應下方。
- AI 聊天: 是一次多輪的 AI 對話,可以在其中定義檢索策略 (可以使用加權重排序分數來替代混合搜索中的加權向量相似度) 並選擇聊天模型。在 AI 聊天中,您可以針對具體情况設置高级 RAG 策略,例如知識圖譜、自動關鍵詞和自動提問。 檢索到的訊息不會與答案一起顯示。在設定聊天助手時,可以使用 AI 搜索作為参考來驗證模型設定和檢索策略。
為什麼檔案解析的進度總是停在 1% 以下 ?
點擊 解析狀態 旁邊的红色叉叉,然後重新啟動解析,再查看問题是否仍然存在。如果依舊, 請檢查相關日誌內容,看看是否有任何異常。