驗證
模型驗證提供一個工具,讓使用者可以針對 LLM 模型 (包括微調過的模型) 進行推論結果的比較。除了讓進階的專業人員以人工模式進行驗證之外; 同時亦提供自動化驗證模式以方便一般基礎人員也能達到相同目的。
人工驗證模式
此模式允許您透過評估模型對指定問題集的回應,來評估模型在不同訓練階段 訓練輪次 的效能。
配置選項
- 最大 Token 數:允許用戶設定模型生成的最大 token 數限制。
- 推理溫度:調整模型輸出的隨機性,促進確定性或創造性回應。
- TopP:讓用戶能夠微調採樣技術以獲得更好的回應品質。
模型選單
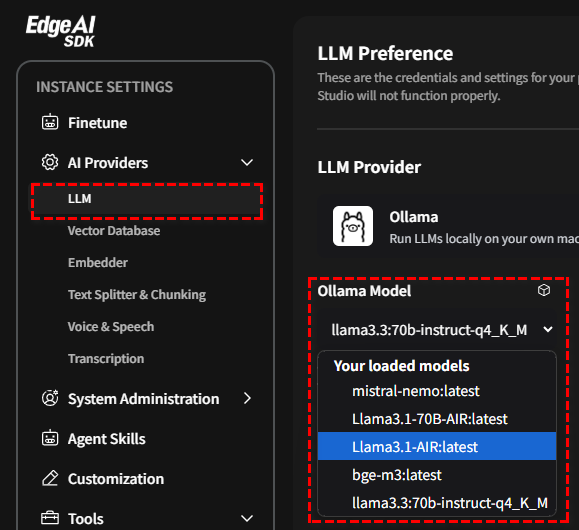
- 用戶可以從多個可用於驗證的模型中進行選擇。
- 點擊模型清單可讓您從各種可用模型中進行選擇。這些包括預訓練的基礎模型和針對特定任務微調的自訂模型。
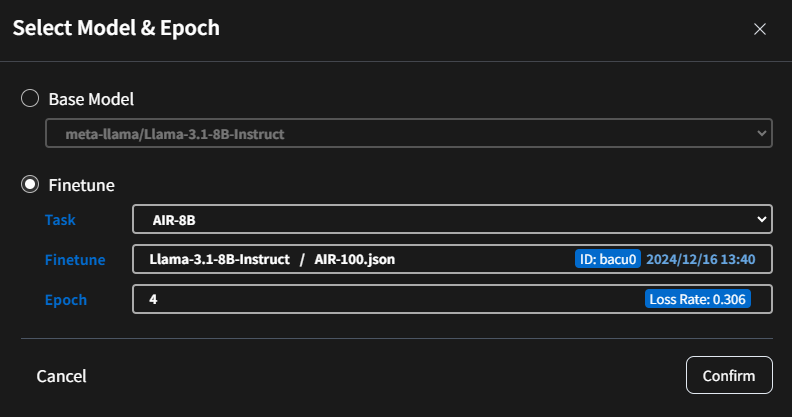
- 範例:
- 基礎模型:
meta-llama/Llama-3.1-8B-Instruct - 微調後模型:
AIR-8B -第 4 週期。
- 基礎模型:
並排輸出比較
- 介面以並排方式顯示不同模型的輸出,便於比較。
- 每一欄對應一個具有特定參數的模型。
問題輸入區域
- 專用的輸入欄位,用於輸入要驗證的問題或提示。
- 用戶可以使用介面底部的文字輸入區域新增問題,或上傳 JSON 檔案來提供批量問題。
訊息
提供的 JSON 程式碼片段符合標準 JSON 格式。它由一個清單(以方括號 [] 表示)組成,包含多個字串,每個字串代表一個問題。
例如:
[
"What processor is integrated into the AIR-100 system?",
"What graphics engine is used for HDMI-1 and HDMI-2 outputs in the AIR-100?",
"How many HDMI outputs does the AIR-100 support, and what are their versions?"
]
動作按鈕
- 送出:根據當前配置啟動驗證過程。
- 重設:清除所有問題輸入。
驗證並比較模型
點擊 送出 後,系統將使用提供的問題查詢兩個模型。在此過程中,當模型載入到 GPU 時會有短暫的載入時間。一旦模型生成回應,
每個答案旁邊會出現一個「讚」![]() 的圖示。如果您對特定回應滿意,請點擊對應的圖示。系統會記錄每個模型收到的
「讚」數量,這將用於後續的模型量化。
的圖示。如果您對特定回應滿意,請點擊對應的圖示。系統會記錄每個模型收到的
「讚」數量,這將用於後續的模型量化。
- 情況 I:
基礎模型vs微調模式(第 4 週期)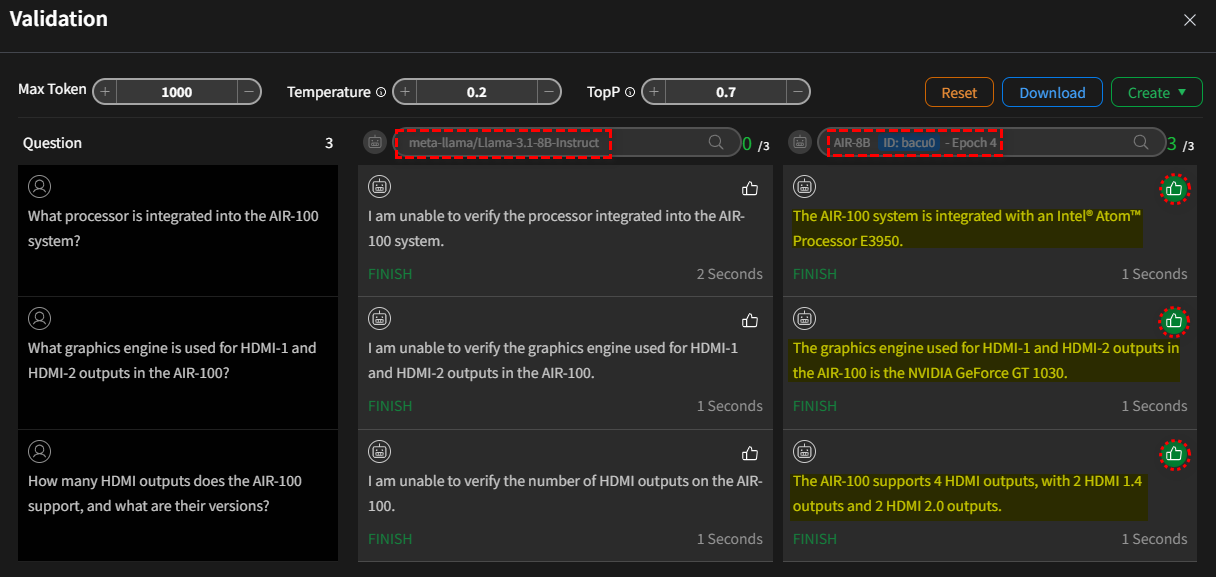
- 情況 II:
微調模式(第 1 週期)vs微調模式(第 4 週期)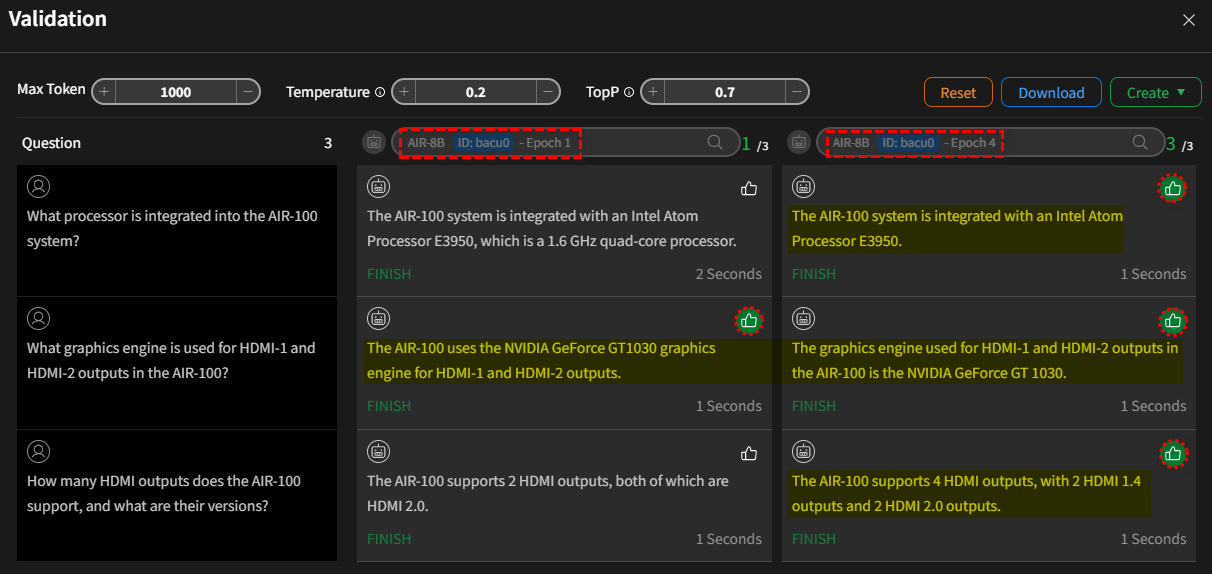
動作按鈕 (完成驗證)
在完成模型驗證之後,畫面右上方的會多出二個按鈕:
- 下載:將問題及其對應的模型生成答案下載為 CSV 檔案。
- 創建:
-
建立工作區:量化模型並直接創建新的工作區,套用量化後的模型。預設量化格式為
q4_k_m。 模型選擇清單將顯示來自各個訓練輪次的微調模型。將包含用戶對每個模型回應評分的統計摘要,以協助您進行選擇。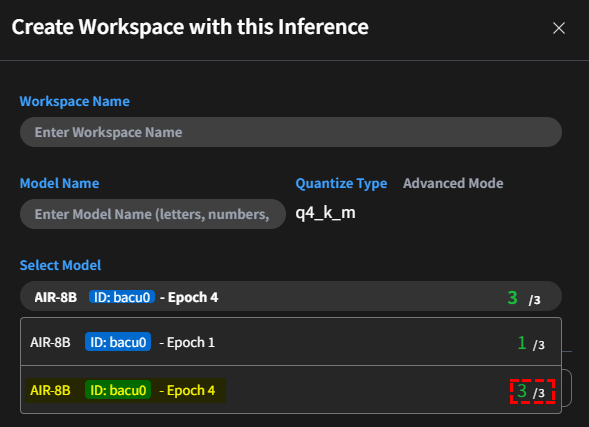 訊息
訊息Q_K_M 配置的設計目的是:
- 減少記憶體使用:透過降低權重精度,模型可以在有限 RAM 的設備上執行。
- 提升推理速度:量化模型需要更少的計算資源,使其更快速。
- 維持可接受的準確性:像 K 型這樣的進階量化方法旨在最小化因精度降低而導致的模型效能損失。
例如,在 llama.cpp 中,Q4_K_M 模型使用 4 位元量化配合 K 型最佳化,在記憶體效率和模型準確性之間取得平衡。
Q_K_M 的組成部分:
- Q:
- 代表 量化,一個減少模型權重精度的過程(例如從 16 位元浮點數到 4 位元整數)。
- 量化減少了記憶體佔用並加速推理,特別是在資源受限的設備上。
- K:
- 指的是 K 型量化方法,這是用於最佳化量化過程的特定演算法或方法。
- K 型量化通常專注於最小化困惑度損失(模型效能的衡量標準),同時維持效率。 它通常比簡單的量化方法更進階。
- M:
- 可能代表量化方法內的一個 模式 或 配置。例如:
- M 可能意味著「中等」,表示效能和效率之間的平衡。
- 其他後綴(例如 S 代表「小」或 L 代表「大」)可能代表速度、記憶體使用和準確性之間的不同權衡。
- 可能代表量化方法內的一個 模式 或 配置。例如:
-
匯入到 Ollama 的推理儲存庫:將模型放置到 Ollama 可以存取和使用的儲存庫中。
-
一旦模型被壓縮,您可以在 AI 提供者部分的 LLM 下的 Ollama 中找到它。