Validation
Model validation provides a tool that allows users to compare inference results for LLM models (including fine-tuned models). In addition to allowing advanced professionals to perform validation in manual mode, it also provides an automated validation mode to enable basic personnel to achieve the same purpose.
Manual Validation Mode
This mode allows users to assess model performance at different training stages (epochs) by evaluating their
responses to a given set of questions.
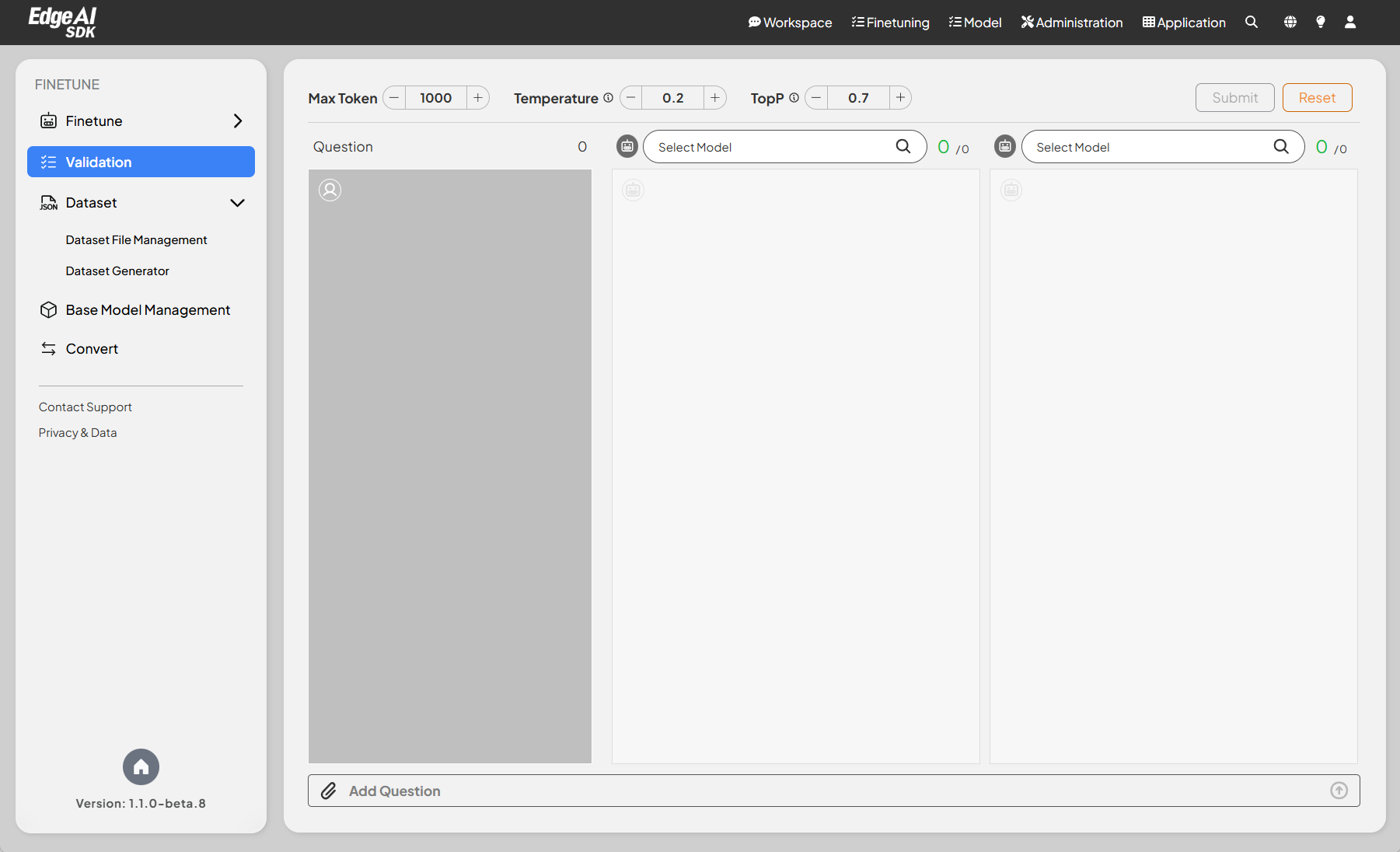
Configuration Options
- Max Token: Allows users to set a limit on the maximum number of tokens generated by the model.
- Temperature: Provides a slider to adjust the randomness of the model's outputs, promoting deterministic or creative responses.
- TopP: Enables users to fine-tune the sampling technique for better response quality.
Model Selection
- Users can select from multiple models available for validation.
- Clicking on the model list allows you to choose from a variety of available models. These include both pre-trained
base models and custom models that have been fine-tuned for specific tasks.
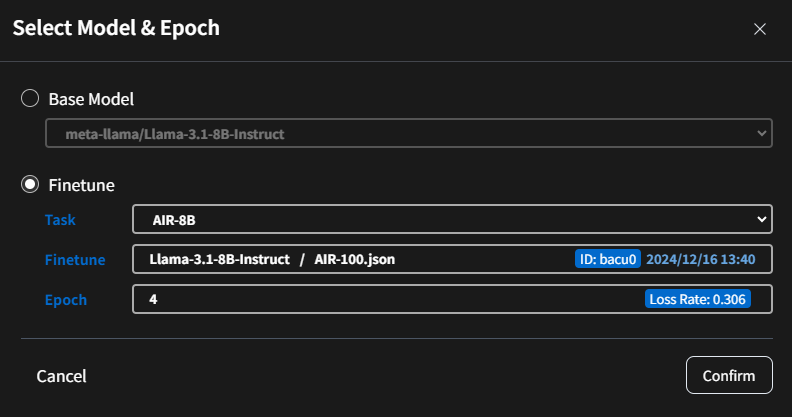
- Example:
- Foundation Model:
meta-llama/Llama-3.1-8B-Instruct - After Fine-tuning Model:
AIR-8B -Epoch 4.
- Foundation Model:
Side-by-Side Output Comparison
- The interface displays outputs from different models or configurations in parallel for easy comparison.
- Each column corresponds to a model with its specific parameters.
Question Input Area
- A dedicated input field for entering questions or prompts to be validated.
- Users can add questions using the text input area at the bottom of the interface or upload a JSON file to provide a batch of questions.
The provided JSON snippet adheres to the standard JSON format. It consists of a list (indicated by square brackets []) containing multiple strings, each representing a question.
For Example:
[
"What processor is integrated into the AIR-100 system?",
"What graphics engine is used for HDMI-1 and HDMI-2 outputs in the AIR-100?",
"How many HDMI outputs does the AIR-100 support, and what are their versions?"
]
Action Buttons
- Submit: Initiates the validation process based on the current configuration.
- Reset: Clears all question inputs.
Validate and Compare the Model
Upon clicking submit, the system will query both models with the provided question. During this process,
there will be a brief loading time as the models are loaded onto the GPU. Once the models have generated their
responses, a "like" ![]() icon will appear next to each answer. If you are satisfied with a
particular response, please click the corresponding icon. The system will record the number of "likes" each model
receives, which will be used for subsequent model quantification.
icon will appear next to each answer. If you are satisfied with a
particular response, please click the corresponding icon. The system will record the number of "likes" each model
receives, which will be used for subsequent model quantification.
- Case I:
Foundation ModelvsFine-tuning Mode (Epoch 4)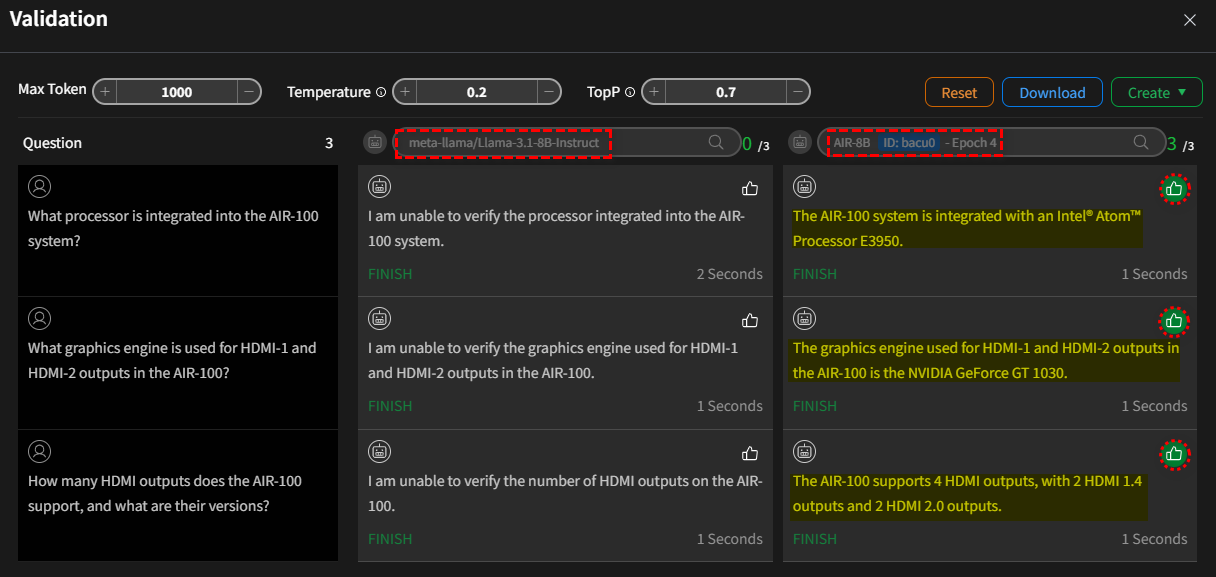
- Case II:
Fine-tuning Mode (Epoch 1)vsFine-tuning Mode (Epoch 4)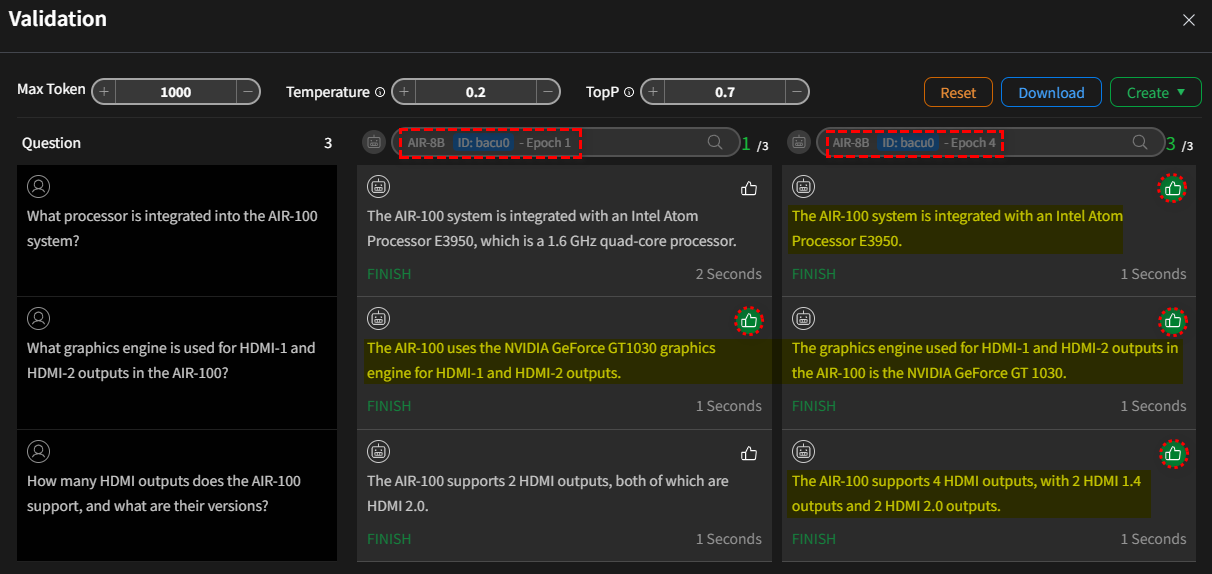
Action Buttons (Validation Completed)
After validation, two additional action buttons will appear in the upper right corner of the screen:
- Download: Download the questions and their corresponding model-generated answers as a CSV file.
- Create:
-
Create Workspace with this inference: Quantize the model and create a new Workspace directly, applying the quantized model. The default quantization format is
q4_k_m. Advanced quantization options are available in advanced mode. The model selection list will display fine-tuned models from various training epochs. A statistical summary of user ratings for each model's responses will be included to aid in your selection.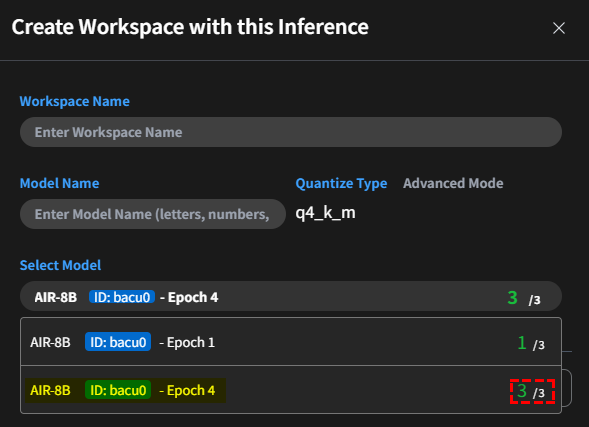 info
infoThe Q_K_M configuration is designed to:
- Reduce memory usage: By lowering the precision of weights, models can run on devices with limited RAM.
- Improve inference speed: Quantized models require fewer computational resources, making them faster.
- Maintain acceptable accuracy: Advanced quantization methods like K-type aim to minimize the loss in model performance caused by reduced precision.
For example, in llama.cpp, a Q4_K_M model uses 4-bit quantization with K-type optimization, striking a balance between memory efficiency and model accuracy.
Breaking Down Q_K_M:
- Q:
- Represents Quantization, a process of reducing the precision of model weights (e.g., from 16-bit floating point to 4-bit integers).
- Quantization reduces the memory footprint and speeds up inference, especially on resource-constrained devices.
- K:
- Refers to a K-type quantization method, which is a specific algorithm or approach used to optimize the quantization process.
- K-type quantization typically focuses on minimizing perplexity loss (a measure of model performance) while maintaining efficiency. It is often more advanced than simpler quantization methods.
- M:
- Likely stands for a mode or configuration within the quantization method. For example:
- M could mean "Medium," indicating a balance between performance and efficiency.
- Other suffixes (e.g., S for "Small" or L for "Large") might represent different trade-offs between speed, memory usage, and accuracy.
- Likely stands for a mode or configuration within the quantization method. For example:
-
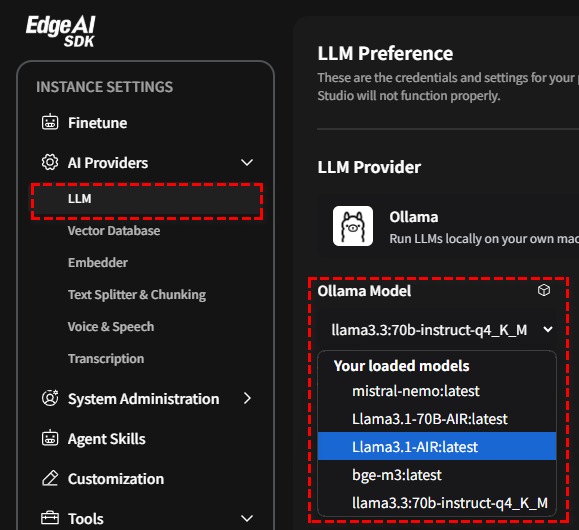
Import to Ollama's Inference Repo: To place a model into a repository that Ollama can access and use.
-
Once the model is compressed, you can locate it in the AI Provider section, under LLM and then Ollama.