全參數微調
選擇 新增任務 並指定任務名稱後,訓練工作流程就會開始。該過程分為四個主要步驟: 設置、
訓練、 驗證 和 完成。
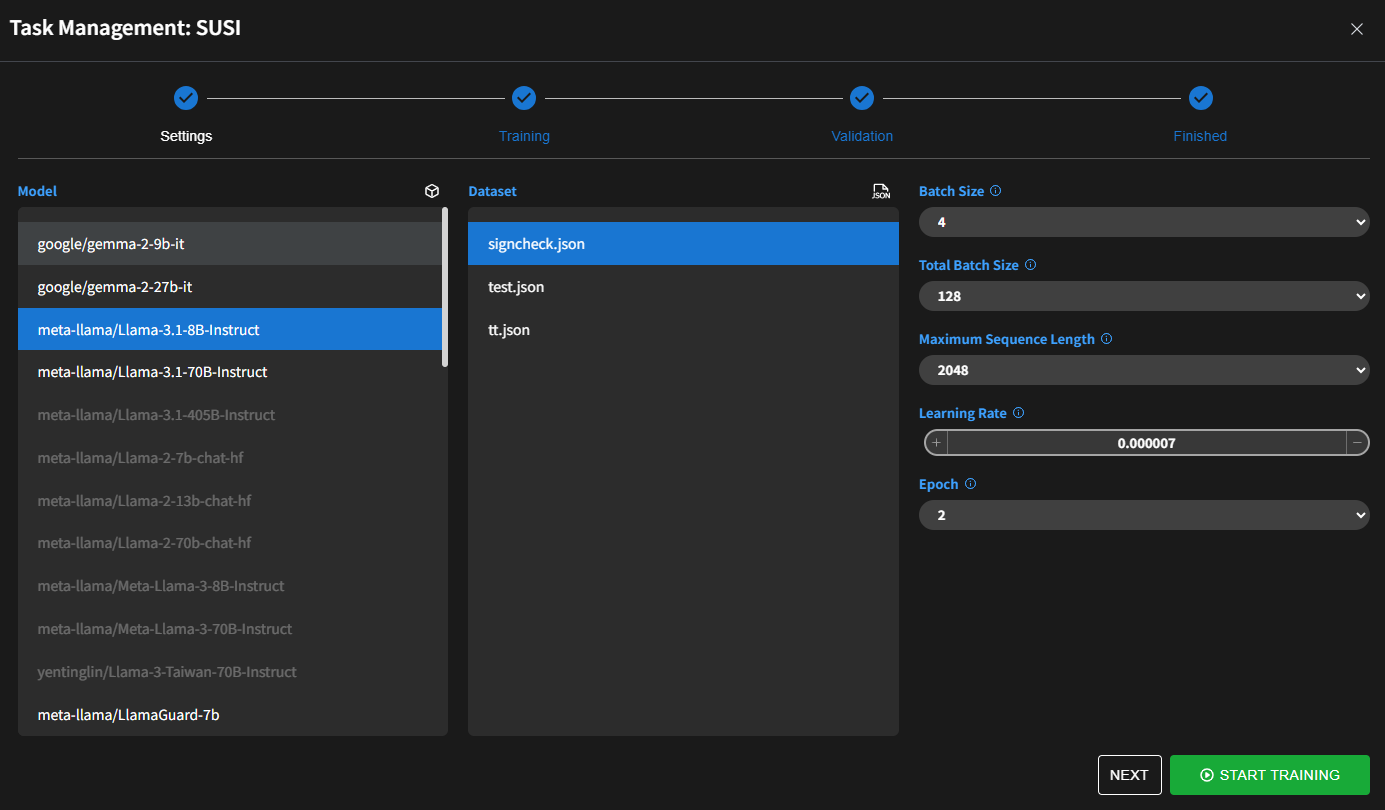
步驟 1:設置
在此步驟中,用戶配置用於訓練的模型和資料集,並定義訓練參數。
模型選擇
- 從清單中選擇要微調的模型。
- 如果所有模型都是灰色的,表示模型尚不可用。要下載模型:
- 點擊「模型」旁邊的圖示
 以打開
模型管理 視窗。
以打開
模型管理 視窗。 - 使用模型管理介面下載所需的模型。
- 點擊「模型」旁邊的圖示
資料集選擇
- 從清單中選擇現有資料集。
- 如果資料集清單為空,可以透過以下方式上傳或生成資料集:
- 點擊「資料集」旁邊的圖示
 以打開
資料集管理 視窗。
以打開
資料集管理 視窗。 - 在資料集管理介面中,您可以上傳資料集或使用 LLM 根據您的輸入檔案(例如 PDF、Word 文件)生成資料集。
- 點擊「資料集」旁邊的圖示
訓練參數
配置以下參數:
- 批次大小
- 含義:模型在訓練期間一次處理的資料樣本數量。就像一口氣學習書本的 10 頁;這 10 頁就是批次大小。
- 重要考量:
- 太小:模型可能無法有效學習,訓練可能變得不穩定。
- 太大:需要更多記憶體(例如 GPU VRAM)並可能減慢訓練速度。
- 總批次大小
- 含義:如果您使用多個 GPU 進行訓練,這是所有 GPU 上批次大小的總和。例如,如果每個 GPU 處理 32 個樣本且您有 4 個 GPU,總批次大小就是 32 × 4 = 128。
- 重要考量:
- 整體大小影響學習:較大的大小可以穩定訓練,但可能需要調整其他參數,如學習率。
- 最大序列長度
- 含義:模型在一個輸入中處理的最大標記數(單詞、子詞或字符)。可以將其視為模型一次能讀取的句子或段落的最大長度。
- 重要考量:
- 較長序列: 提供更多上下文,但需要更多記憶體和計算能力。
- 較短序列: 處理速度更快,但可能失去重要上下文。
- 學習率
- 含義:模型在每個訓練步驟中調整其參數的幅度。就像決定朝目標走路時步伐有多大。
- 重要考量:
- 太高: 模型可能會超過最佳解決方案,導致不穩定。
- 太低: 訓練變慢,模型可能困在次優解決方案。
- 訓練週期
- 含義:完整遍歷整個訓練資料集一次。如果您有一本 100 頁的書,讀完所有 100 頁一次就是一個訓練週期。
- 重要考量:
- 週期太少: 模型可能欠擬合(從資料中學習不足)。
- 週期太多: 模型可能過擬合(記住資料而不是很好地泛化)。
所有配置完成後,點擊 開始訓練 進入下一步。
步驟 2:訓練
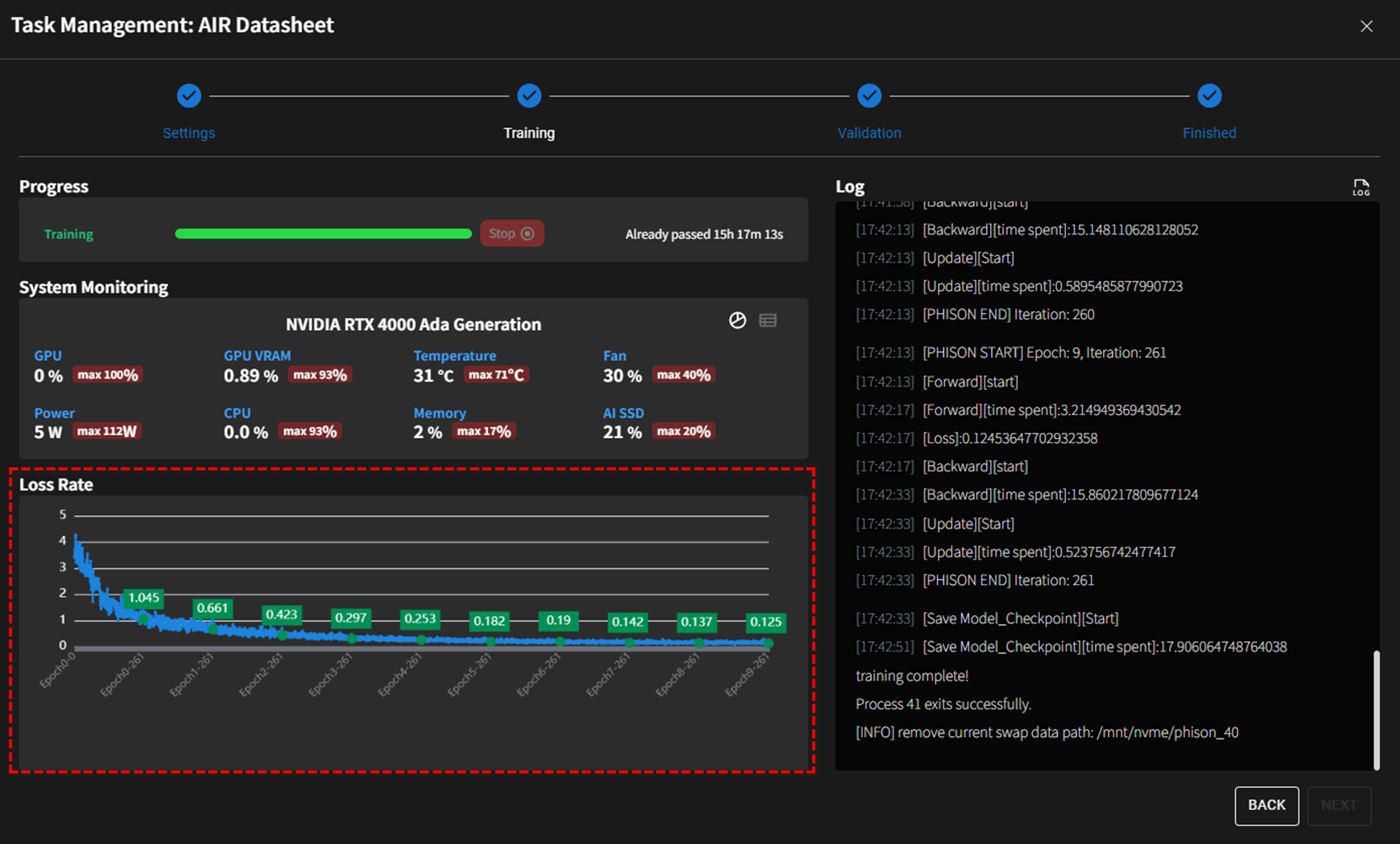
訓練進度概覽
- 進度條顯示訓練的即時狀態,以及已耗時間(例如
15h 17m 13s)。 - 用戶可以點擊
停止按鈕立即停止訓練過程。
系統監控指標
- GPU 使用率: 包括 GPU 使用的即時和最大值(例如
0%)。 - VRAM 使用量: 顯示當前(例如
0.89%)和峰值(例如93%)記憶體使用量。 - 溫度: 追蹤 GPU 的溫度(例如
31°C)和峰值(例如71°C)。 - 風扇速度: 顯示即時風扇速度佔其最大容量的百分比(例如
30%)和峰值(例如40%)。 - CPU 使用率: 顯示即時和峰值 CPU 使用率(例如
0%)和峰值(例如93%)。 - 記憶體使用率: 顯示系統的記憶體使用量(例如
2%)和峰值(例如17%)。 - AI SSD 使用量: 監控專門分配給 AI 操作的 SSD 使用量(例如
21%)和峰值(例如20%)。
損失率視覺化
- 動態圖表追蹤各訓練週期的 損失率。
- 圖表突出顯示損失率的改善:
- 此視覺化讓用戶快速評估訓練效果和收斂趨勢。
關於損失率
損失率是訓練期間要監控的主要指標,理想情況下應該隨著每個訓練週期而下降。
詳細日誌
- 即時日誌提供關於訓練迭代的詳細資訊,包括特定時間戳和執行的操作(例如
Forward、Backward、Save Model_Checkpoint)。- 用戶可以點擊 Log 區段旁邊的圖示
 立即下載詳細的日誌檔案。
立即下載詳細的日誌檔案。
- 用戶可以點擊 Log 區段旁邊的圖示
步驟 3:驗證和量化
驗證概覽 模型驗證提供了並排比較多個大型語言模型 (LLM) 的工具,包括微調模型。它透過分析對給定問題集合的回應來評估不同訓練階段(例如 訓練週期)的模型性能。
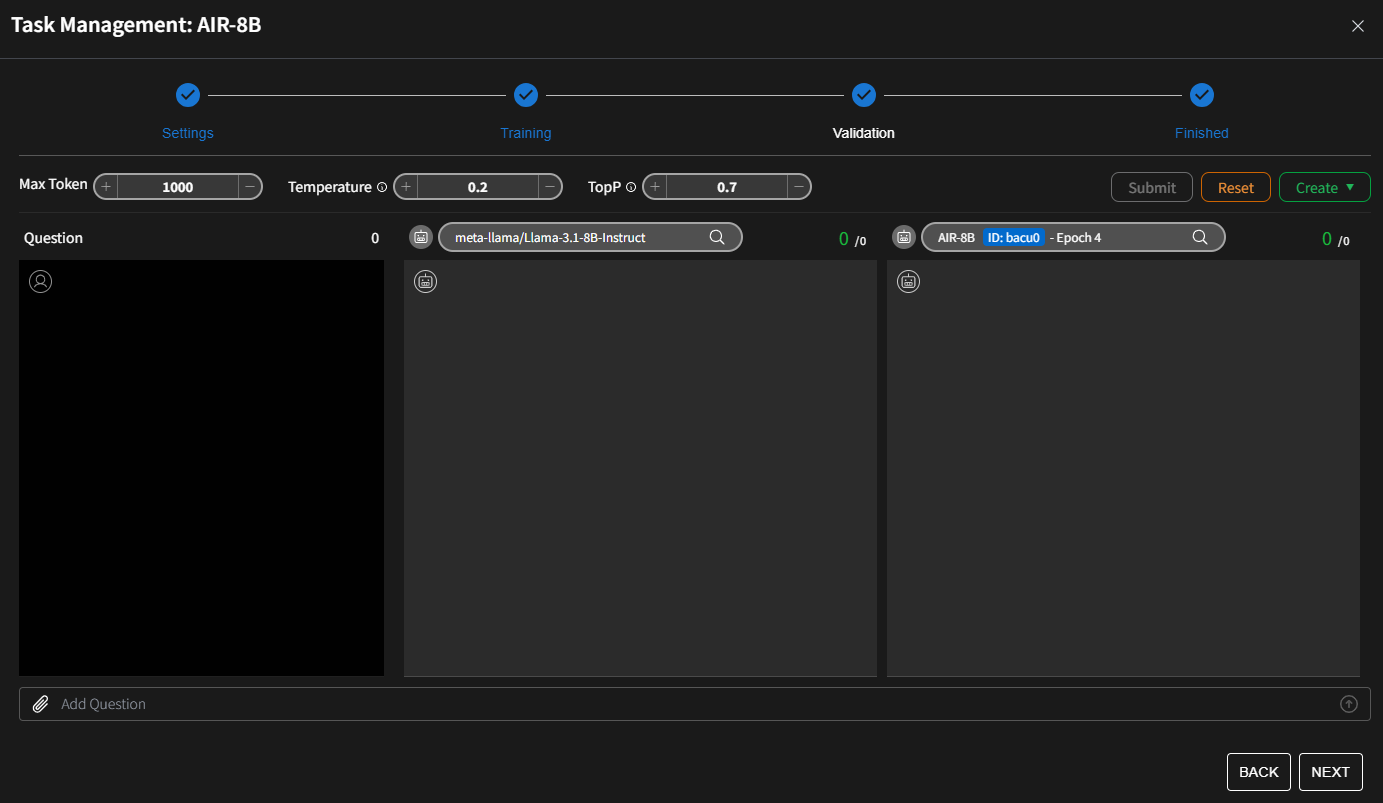
要獲得關於有效利用此功能的更詳細說明和範例,我們鼓勵您造訪 驗證 操作頁面。此頁面提供全面的指導,包括逐步程序、最佳實踐和故障排除提示,確保您能最大化功能的能力並有效應用以滿足您的需求。
步驟 4:完成
成功完成模型驗證和量化後,您將被重定向到指定的模型儲存庫 (Ollama) 或您指定的工作區。
