Version 1.0
New Features
This update introduces the ability for full-parameter fine-tuning of the LLM Model in Anything LLM base. The key features include:
- Model Downloading
- Dataset Generation
- Model Fine-tuning (Full-parameter)
- Model Validation
- GPU Resource Management
- Scheduling for Fine-tuning
This system is designed with NVIDIA GPUs to deliver these functions.
Model Downloading
GenAI Studio facilitates seamless downloading of LLM models from Hugging Face, with supported models displayed directly
in the user interface. To download a model, you will need a user access token
. For more details, refer to the Hugging Face documentation.
Some models, such as LLAMA, require user consent for sharing contact
information before download.
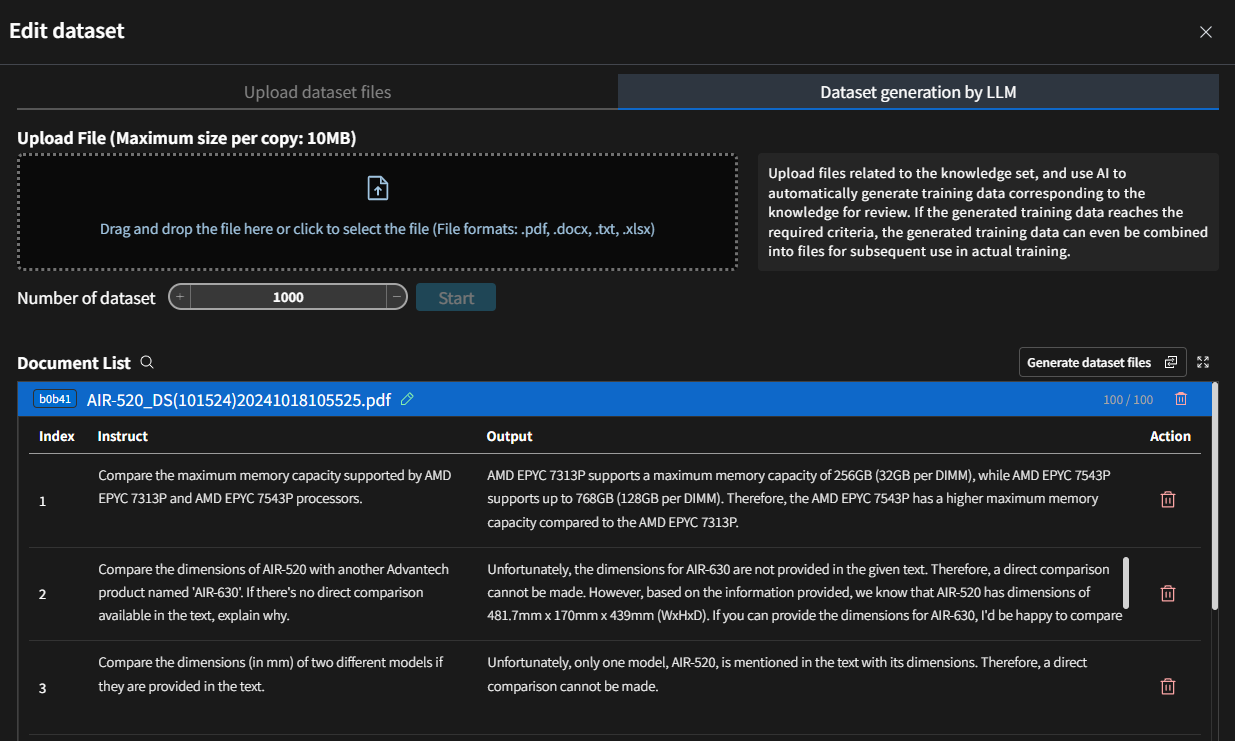
Dataset Generation
Creating datasets for domain-specific training is simplified with GenAI Studio. Upload your domain files (e.g., PDFs, Word documents), and the system will generate a dataset based on your input. Features include:
- Editable datasets online.
- The ability to merge datasets from multiple documents.
- Configurable file size limits (default: 10 MB).
The file size limit is set to 10 MB, but it can be adjusted in the system settings if needed.
Model Fine-tuning (Full-parameter)
Task Oriented Approach
Fine-tuning is managed through a task-oriented system, allowing dedicated tasks for different domains. Users can:
- Select specific models, parameters, and datasets.
- Customize the training process for their needs.
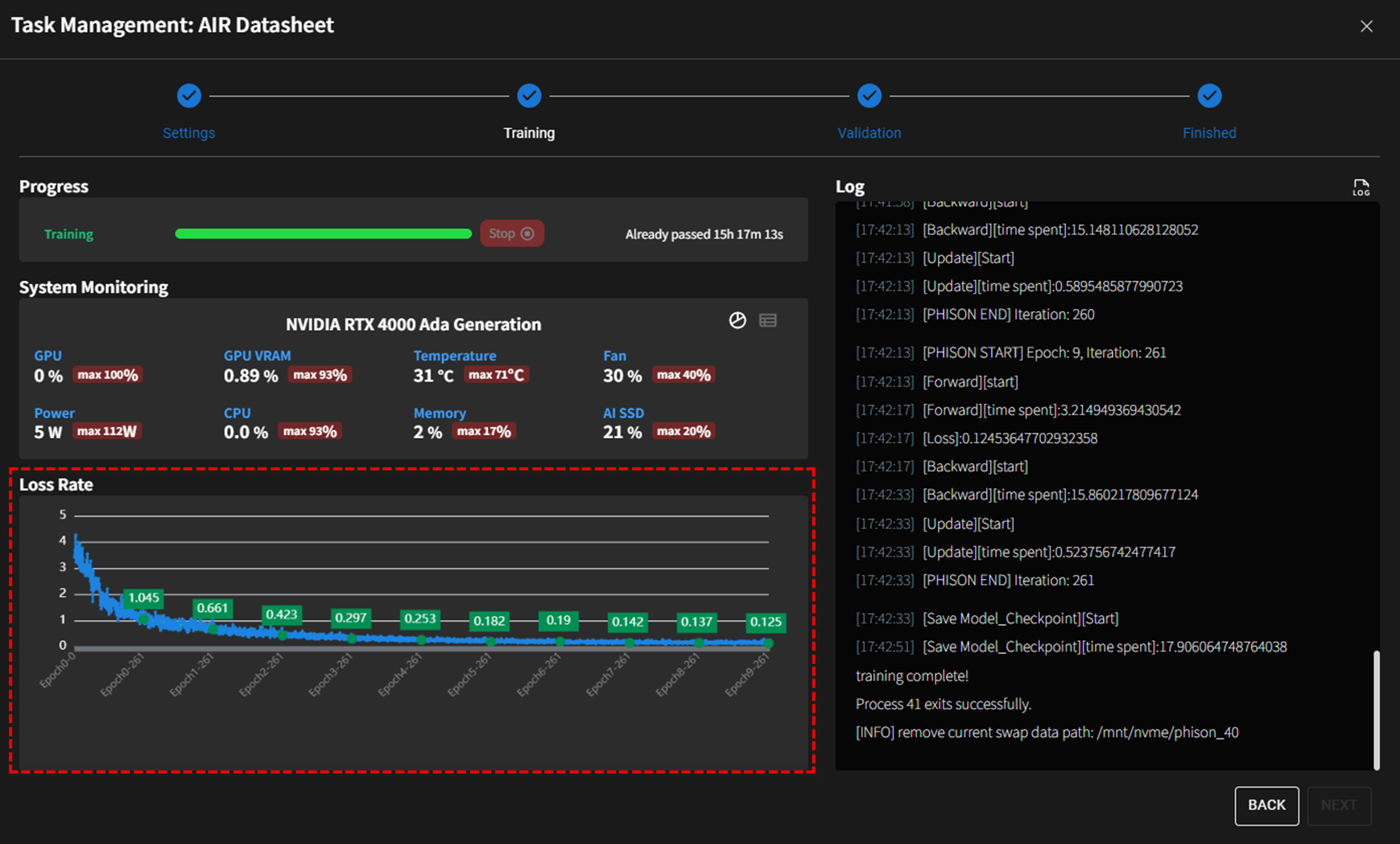
Fine-tuning Process
The full-parameter fine-tuning process utilizes GPU resources and provides real-time logs. Key considerations:
- Loss Rate: The primary metric to monitor during training, which should ideally decrease with each epoch.
- Overfitting: Avoid excessive epochs to prevent overfitting.
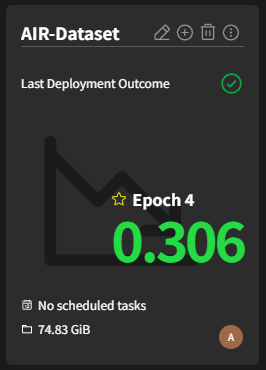
Fine-tune History
Records of previous training sessions, including parameters and configurations, are maintained to assist users in refining future training efforts.
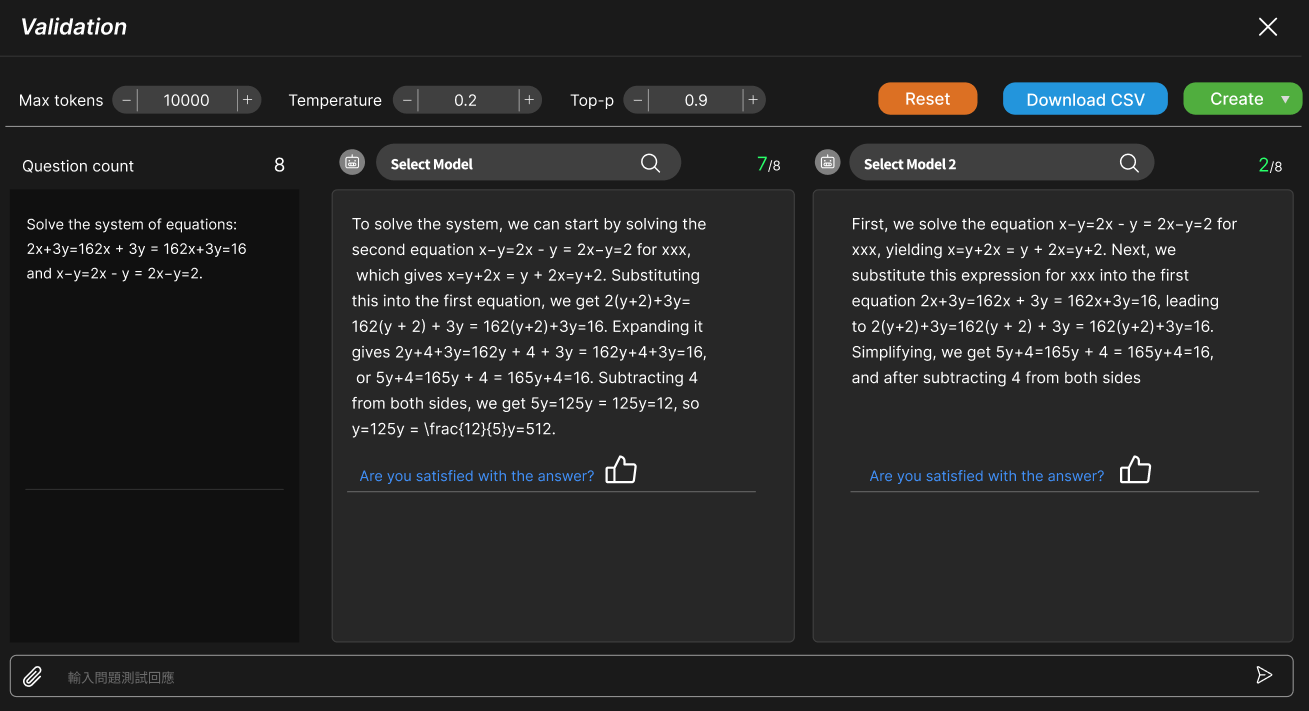
Model Validation
Compare the original model with the fine-tuned version to assess the effectiveness of training. This ensures the desired knowledge is successfully integrated.
GPU Resource Management
Efficient GPU usage is critical for cost-effectiveness. GenAI Studio provides the following GPU resource management modes:
-
As-Is Mode The system does not impose any restrictions on GPU resources. Under this mode, GPU resources are usually allocated on a first-come, first-served basis.
-
Training Dedicated Mode The system restricts GPU resources to be used only for model training or related processes (such as validation, quantization, etc.). If the model training process is expected to take more than 12 hours, it is recommended to switch to this mode before starting the training to avoid the training process being forcibly interrupted before results are generated.
-
Time-Slot Mode The system controls GPU resources based on the scheduled time slots, allowing them to be used for chat-related functions or model training-related functions. Please adjust the following settings according to the organization's needs to control which time slots GPU resources are used for chat-related functions. Time slots outside these settings are used for model training-related functions.
Note: When the time enters the chat-related function time slot, the system will forcibly interrupt any ongoing model training-related work.
Scheduling and Fine-tuning
To optimize GPU utilization, training tasks can be scheduled during off-peak hours, such as evenings or weekends.
Third-Party Updates
- Anything LLM (v1.2.4)
- Ollama (v0.5.1)
- Qdrant (v1.12.4)
- PostgreSQL (v16.4)
Phison Middleware Driver
- aiDAPTIVLink Version: NXUN201.00